Chrome DevTools的性能分析的综合指南(翻译)
原文链接:https://blog.jiayihu.net/comprenhensive-guide-chrome-performance/
让我们看看如何切换到 Chrome Devtools Performance 选项卡以有效分析和提高 JavaScript 的性能,同时避免常见错误。我们使用的用例将会提升现实世界canvas库的渲染 FPS。
几周前,我和我的一位同事正在 benchmarks.slaylines.io 上查看画布引擎比较基准。该基准测试列出了几种最流行的解决方案,并可以轻松比较在画布上渲染数千个矩形的性能。
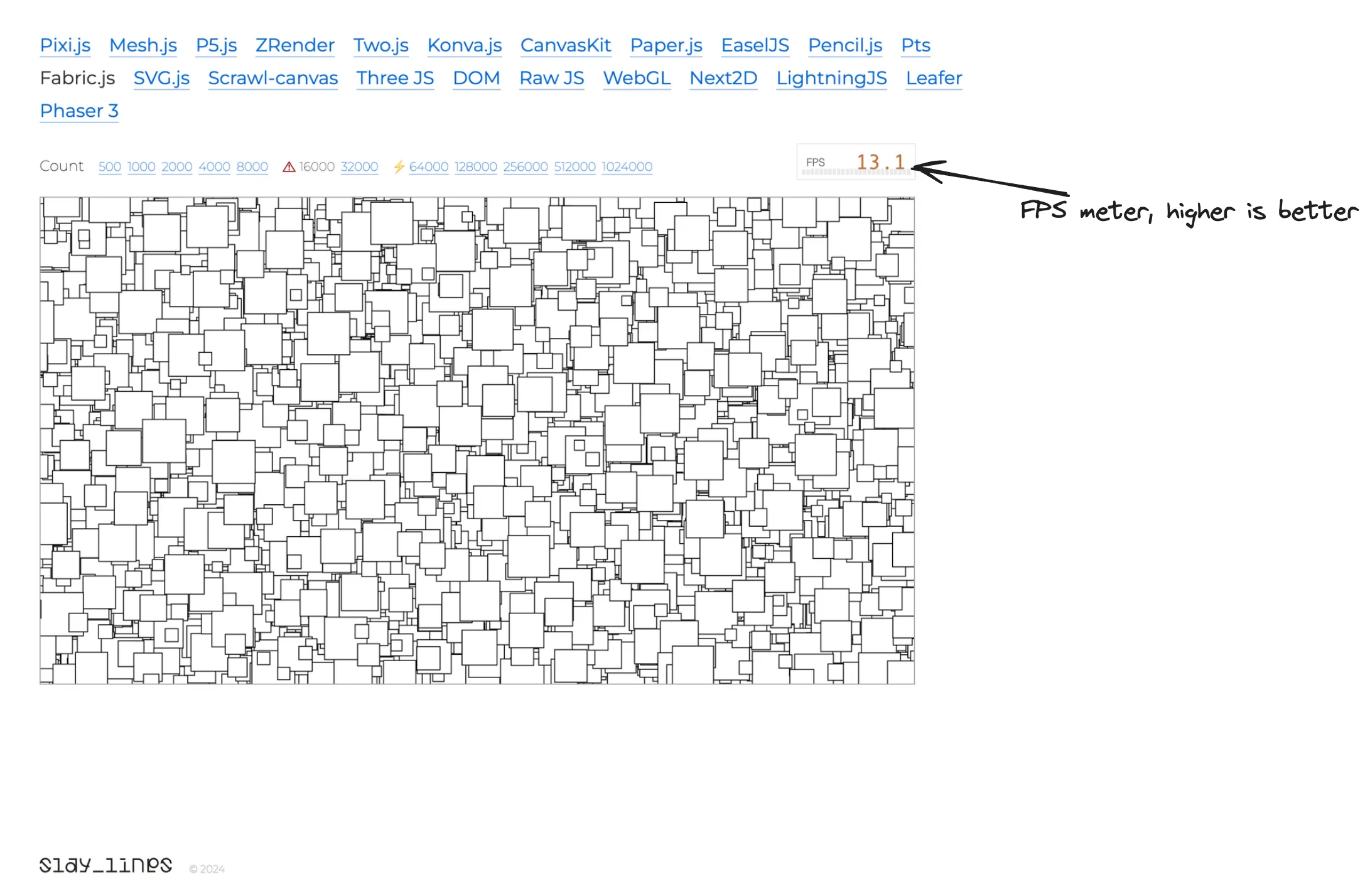
benchmarks.slaylines.io使用Fabric.js和 16000 个对象进行基准测试
在工作中,我们都使用fabric.js,这是一个专注于互动性的画布引擎库,通常会牺牲一些性能。然而,直到我们查看了一个连续动画16,000个对象的基准测试后,才真正意识到它对性能的影响有多大。尽管在一开始我们很担心,但在不到两小时的一次Teams会议中,我们将每秒帧数(FPS)从大约13fps提高到了接近50fps,测量是在M2 Pro上进行的。这意味着在不到两小时内,我们的性能提升了4倍或400%!
我们所做的大部分改动甚至不是画布特定的优化,例如我们并没有从CanvasRenderingContext2D切换到WebGLRenderingContext。所以我想,为什么不利用这个案例来展示我们如何使用Chrome DevTools的性能面板来测量、调查和改进该库的JavaScript执行时间呢?虽然Chrome有关于如何开始分析运行时性能的良好文档,但那更多只是一个介绍,而#分析结果那一部分在解释如何找到可以改进的地方方面远远不够,尤其是在一些复杂情况下。
性能结果的初步概述
在整篇文章中,您可以使用下面这个Code Sandbox尝试性能分析和优化。我准备了基准测试的一个小克隆:
在 fabric.js 文件中,您将找到 OptimisedRect 类,它允许重写一些会对性能产生重大影响的 fabric.Object 类方法。为了测量性能,我建议在新窗口中打开沙盒预览(通过单击右上角的图标),这样基准测试就可以在自己的页面上运行,而不是在 iframe 中。
让我们首先点击 Chrome Devtools 的“性能”选项卡上的“记录”按钮,并首先查看结果。因为在这种情况下我们要处理连续重新渲染,所以我们只需要记录几秒钟,因为执行将定期重复。
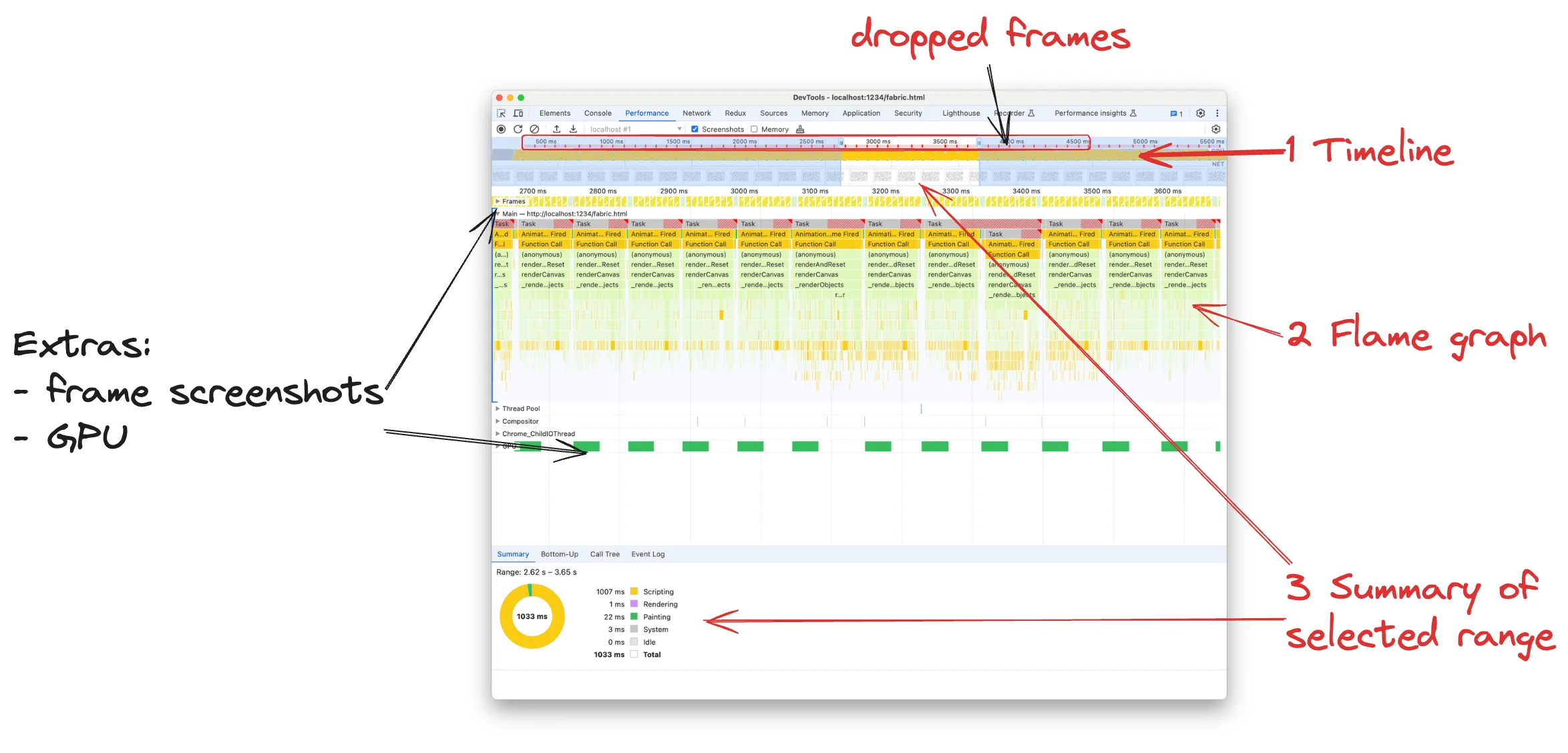
毫无疑问,性能结果在向我们尖叫‘效率低下!’。
时间线
时间轴显示浏览器在录制期间忙于做什么。每种颜色代表不同类型的计算,但通常我们寻找的是代表 JavaScript 执行的黄色。典型的时间线有一些黄色区域的尖峰,其中浏览器正忙于运行 JavaScript 和丢帧:

如果我们正在构建任何重要的应用程序,偶尔丢失一些帧是不可避免的,并且是可以接受的。在时间线上,我们寻找黄色尖峰持续至少半秒的范围。它们对应于许多帧丢失的时刻。时间线底部的屏幕截图对于了解页面上发生的情况非常有用。例如,在我们的例子中,我们可以看到矩形正在移动:
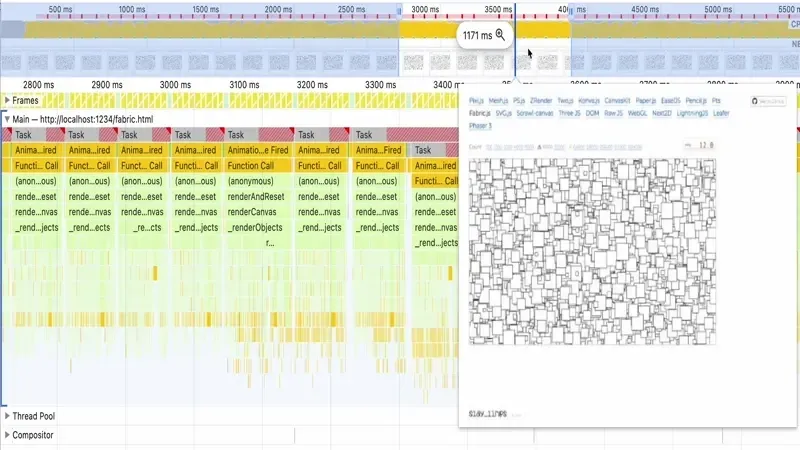
黄色长矩形表示 CPU 一直忙于执行 JavaScript,没有任何空闲时间。这不会是一个问题,因为我们不断地对画布上的矩形进行动画处理和重新渲染,但是时间线顶部的红线和多个红点表明许多帧被丢弃,因为浏览器正忙于执行 JavaScript渲染页面。毫不奇怪,基准测试在 FPS 上显示 12-13fps。
FPS 应至少高于 24,才不会被视为延迟。 30fps 是一个不错的结果,60fps 很棒且流畅,120fps 则是神级的。我们希望达到至少 30fps,这意味着每秒能够渲染 30 次,即 1000 / 30 = 33ms 是我们每帧的总时间。这包括执行我们自己的 JS 来更新画布上的矩形和浏览器的渲染阶段。所以实际上不到 33ms。
您可能认为 FPS 只对动画、画布或游戏重要,但实际上任何网页都需要平滑地重新渲染。即使您只是移动鼠标并悬停链接或按钮,您也需要浏览器重新渲染页面并以不同的背景显示悬停按钮。如果您想知道“如果我不使用画布,如何获得 FPS 仪表?”您可以通过单击 Devtools > 更多工具 > 渲染右上角的三点菜单启用 FPS 渲染统计信息,从 Chrome Devtools 中获取一个。

概况(Summary)
概况(summary)选项卡告诉我们在选定的时间线范围内时间是如何划分的。在我们的例子中,我们选择了 2.62s - 3.65s 之间的范围,所以大约为 1s,并且该时间基本上完全花在运行 JS(黄色脚本)上。浏览器本身只需要 22 毫秒即可完成实际绘制。
虽然概况(summary)选项卡无助于指出性能瓶颈,但它是一个很好的入门指标。当我们深入分析时,它将显示有关我们在火焰图上选择的内容的真正有用的信息。
火焰图
火焰图是我们函数的调用堆栈的图形可视化,一目了然,我们可以看到谁调用了什么。图上的每个节点都对应一个函数,用眼睛遍历图意味着遵循代码路径。我是数据可视化的忠实粉丝,我认为火焰图是最好的可视化工具之一。
在 JavaScript 和 Chrome 的上下文中,火焰图显示从调用者到被调用者的从上到下的调用堆栈。然后,火焰图区域被划分为多个部分,每个事件循环任务对应一个图。在我们的例子中,由于我们正在制作动画,因此每个任务都是一个 requestAnimationFrame 回调,因为这是启动我们任务的“触发器”。在 JS 中,由于我们有事件循环,浏览器是空闲的,除非有一个事件触发任务,即鼠标事件、网络事件、超时触发等。
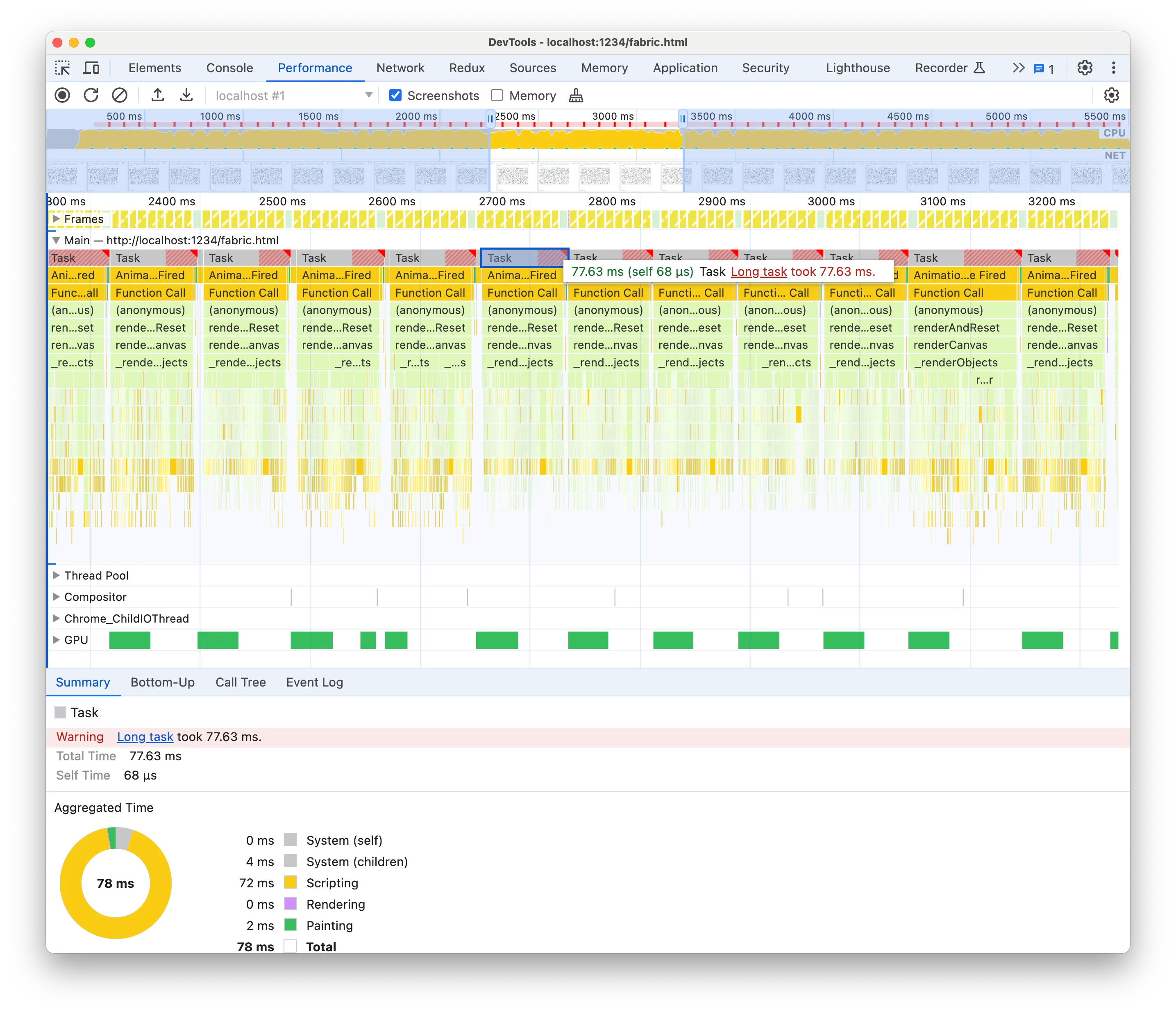
开发工具再次告诉我们每个任务花费的时间太长。如果我们想达到 30fps,我们不应该使用超过 33ms,但每个任务需要 77.63ms,而且这是在 M2 Pro 上!
单击概况(Summary)选项卡中的“长任务”链接将带我们进入 Chrome 文档,其中他们建议将计算拆分为异步块。这通常是不可能的,或者这是一种高级优化,它是高度特定于应用程序的。这不是你能在两个小时内完成的事情!例如,在我们的例子中,在交错帧渲染时异步更新矩形会导致某些矩形的位置不更新或不渲染。将计算拆分为异步块并不是一件容易的事。更常见的是,我们需要减少同步计算,并将异步分块作为最后的高级优化。
Chrome v122 的一个很好的补充是我们甚至可以看到事件任务的发起者,例如谁调用了 setTimeout 或 requestAnimationFrame 。如果您想知道“为什么这段代码正在运行”,这非常方便。
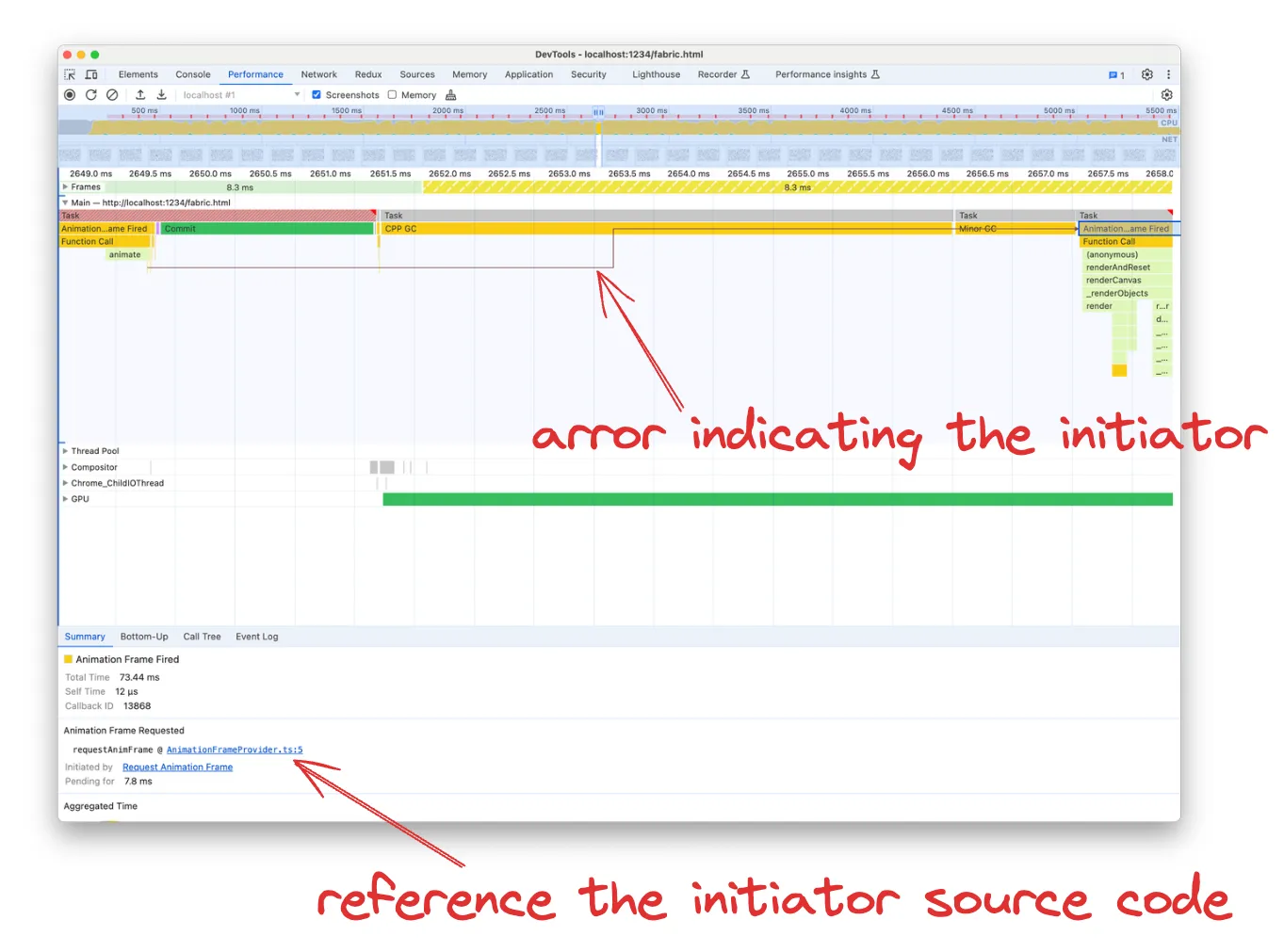
您可以通过返回火焰图中的箭头或打开“摘要”选项卡中的函数“源”来确定启动器。我发现跟随箭头更有用,因为函数引用采用名为 requestAnimationFrame 的确切函数,在我们的例子中它只是一个包装器:
1import { getFabricWindow } from '../../env'; 2 3export function requestAnimFrame(callback: FrameRequestCallback): number { 4 return getFabricWindow().requestAnimationFrame(callback); 5} 6 7export function cancelAnimFrame(handle: number): void { 8 return getFabricWindow().cancelAnimationFrame(handle); 9}
这并不能告诉我们是谁调用的以及为什么被调用。如果你按照火焰图中的箭头,你可以看到调用栈中的父节点。不出所料,在我们的例子中,发起者是一个名为animate的函数,这是一个fabric实用程序,反过来又被一个通用的函数调用。这是因为我们使用了匿名箭头函数,但幸运的是,摘要将提供对函数源代码的引用。
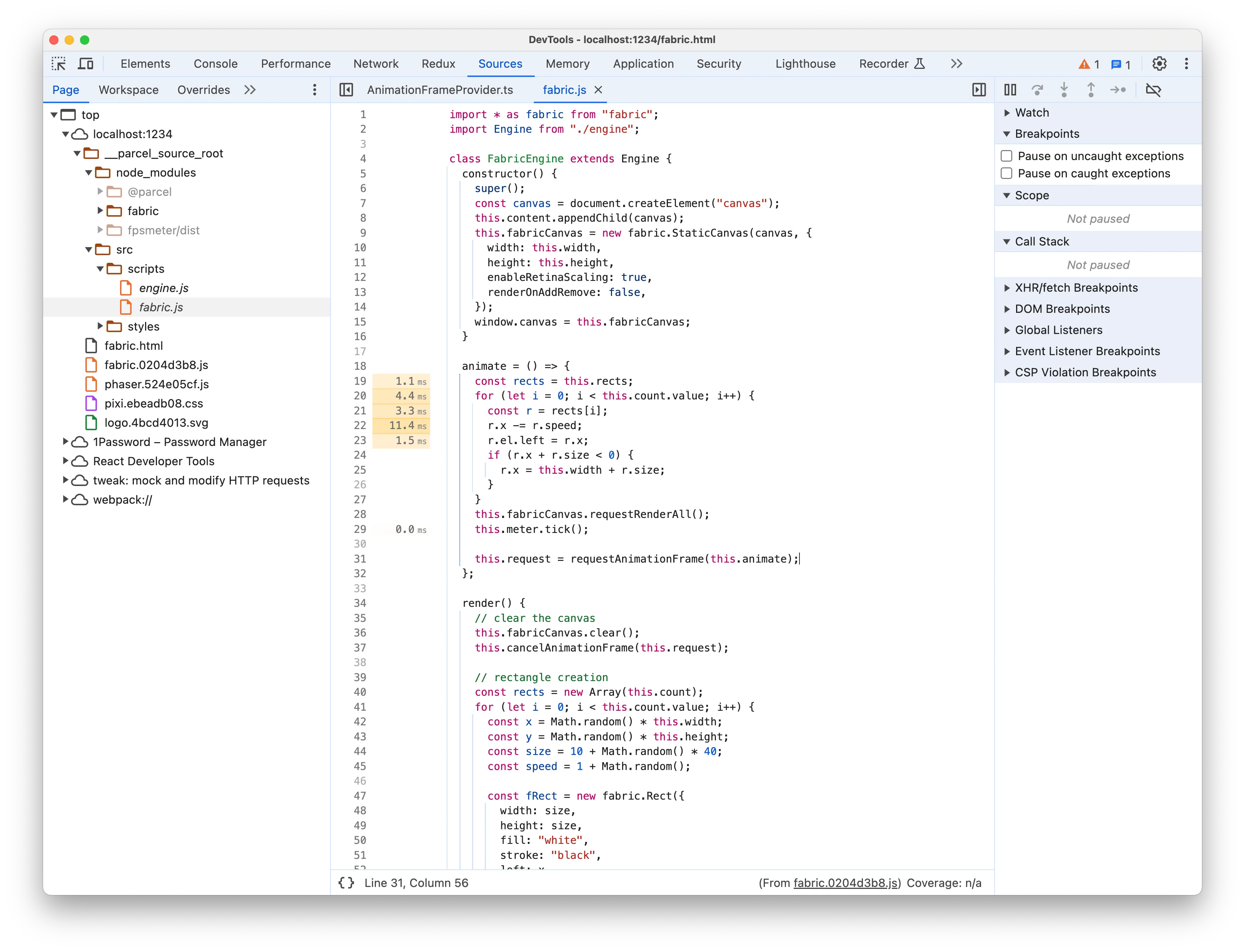
1animate = () => { 2 const rects = this.rects; 3 for (let i = 0; i < this.count.value; i++) { 4 const r = rects[i]; 5 r.x -= r.speed; 6 r.el.left = r.x; 7 if (r.x + r.size < 0) { 8 r.x = this.width + r.size; 9 } 10 } 11 this.fabricCanvas.requestRenderAll(); 12 this.meter.tick(); 13 14 this.request = requestAnimationFrame(this.animate); 15};
该函数也称为 animate ,但这次它是负责更新矩形并要求 Fabric.js 重新渲染每个动画帧的代码。函数中的每一行代码左侧都会有一个数字标签,表示整个记录该行代码执行的总时间。
虽然较大的值会显示为更强烈的黄色,但这并不表明该代码有问题。首先,请记住,这是录制的总时间,而不是每个函数的执行时间。除非您在几秒钟的记录中看到大于数百毫秒的值,否则您根本不用担心。其次,某些代码行比其他行占用更多时间是很自然的,并且差异会在执行过程中累积,因此您经常会看到某些行具有更大的标签时间。在我们的例子中,它似乎表明 r.x -= r.speed 有问题,但当然没有任何问题。
因此,根据我的经验,请仔细评估与源代码中的代码行相关的时间标签。他们经常误导您,您可能会因走错路而浪费时间。
分析火焰图
我们的目标是减少火焰图中每个任务的执行时间。进行性能分析的一个关键方面是首先充分掌握代码试图完成的任务。为此,我们首先选择一个任务并查看图表提供的代码流信息。
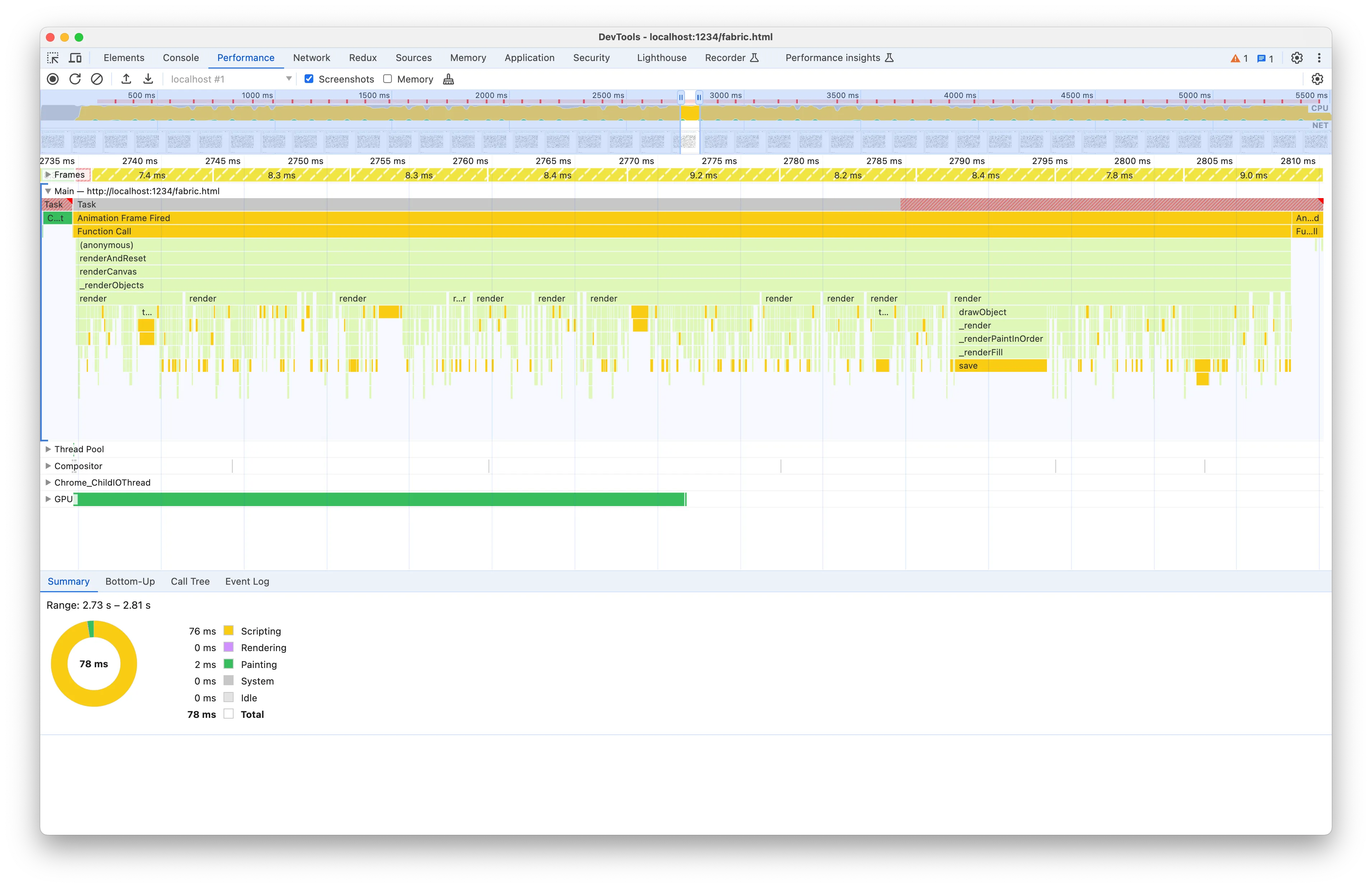
我们可以看到每个任务都以“函数调用”开始,我们看到的是基准测试的 animate 方法。然后我们有一些方法调用导致 _renderObjects 。您会注意到 _renderObjects 之间的节点本身与父节点具有相同的宽度。火焰图中节点的宽度对应于父级执行时间的百分比,因此占据所有父级宽度的节点意味着我们可以忽略父级并在代码路径上向前移动。
例如 renderCanvas 是一个很长的方法,但是因为火焰图向我们显示 _renderObjects 占用了它的所有执行时间,所以我们不需要调查该方法中的其他代码行方法:
这就是为什么熟练阅读火焰图很重要,它可以节省大量时间!当您习惯使用火焰图时,您自然会跳过其子节点占据大部分宽度的节点/函数。但要小心,不要总是立即跳转到火焰图的叶节点,因为您可能会错过具有大量自身执行时间的函数,即花费大量时间执行循环等工作的函数。
继续,我们可以看到 _renderObjects 有几个名为 render 的子节点,包含 _renderObjects 的全部执行时间。通过查看其源代码很容易解释这一点:
1_renderObjects(ctx: CanvasRenderingContext2D, objects: FabricObject[]) { 2 for (let i = 0, len = objects.length; i < len; ++i) { 3 objects[i] && objects[i].render(ctx); 4 } 5}
它所做的只是为画布上的每个对象调用 objects[i].render(ctx) 。

火焰图将向我们显示不同的子节点,称为 render ,其中大多数具有相同的宽度,但有些可能更宽或更窄。 render 节点的数量与它们执行的实际时间不对应(在我们的基准测试中每个矩形执行一次)。函数节点是批处理的,火焰图向我们显示了每个批处理的执行时间。
因此,我们可以选择任何兄弟节点并查看有趣的 render 函数:
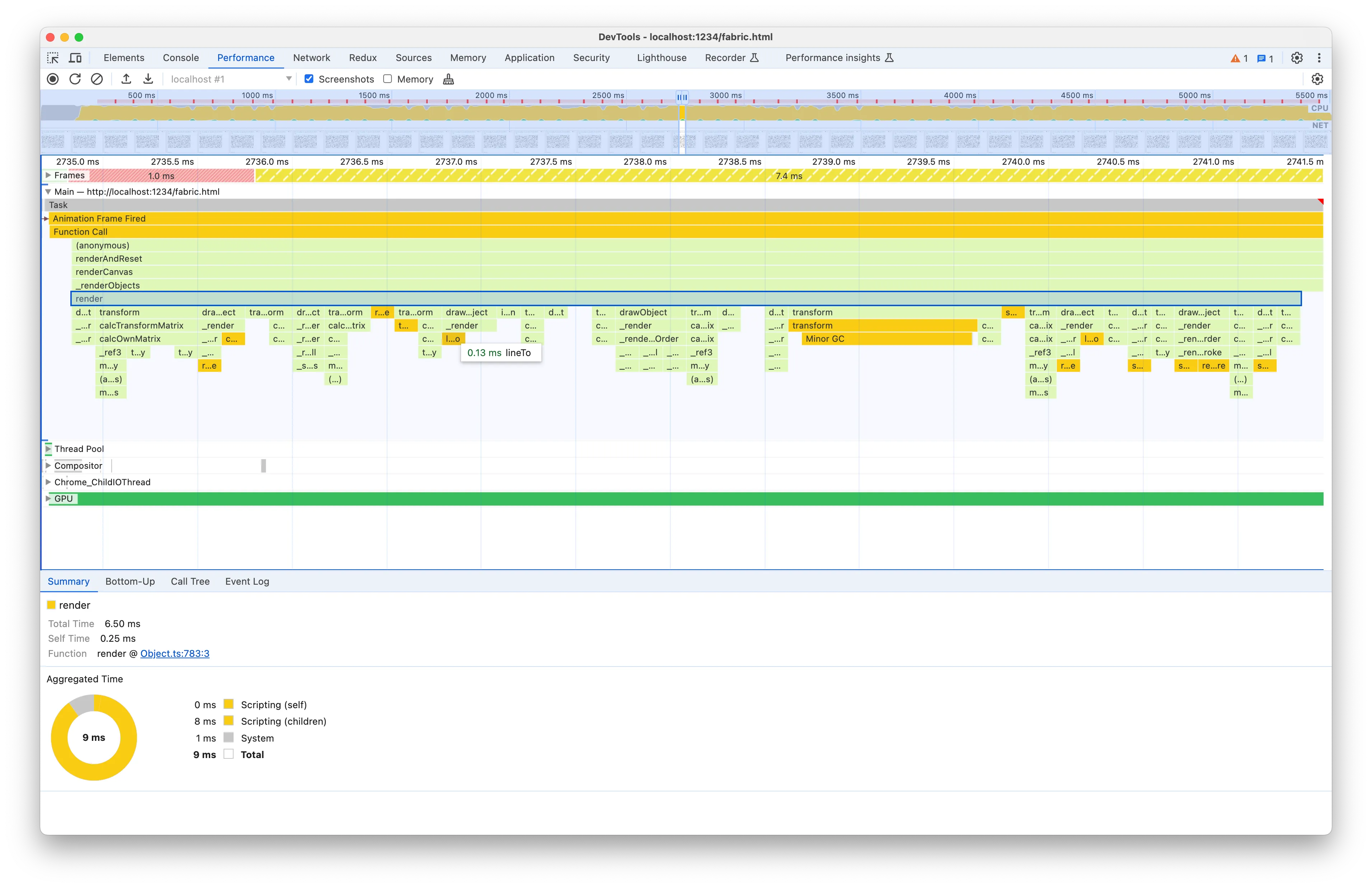
render 方法负责渲染每个对象,特别是我们的基准测试中的每个矩形。与父方法相比,它的子节点更加多样化,而且数量太多,我无法将所有它们的函数名称放入一个屏幕截图中!我们看一下源码:
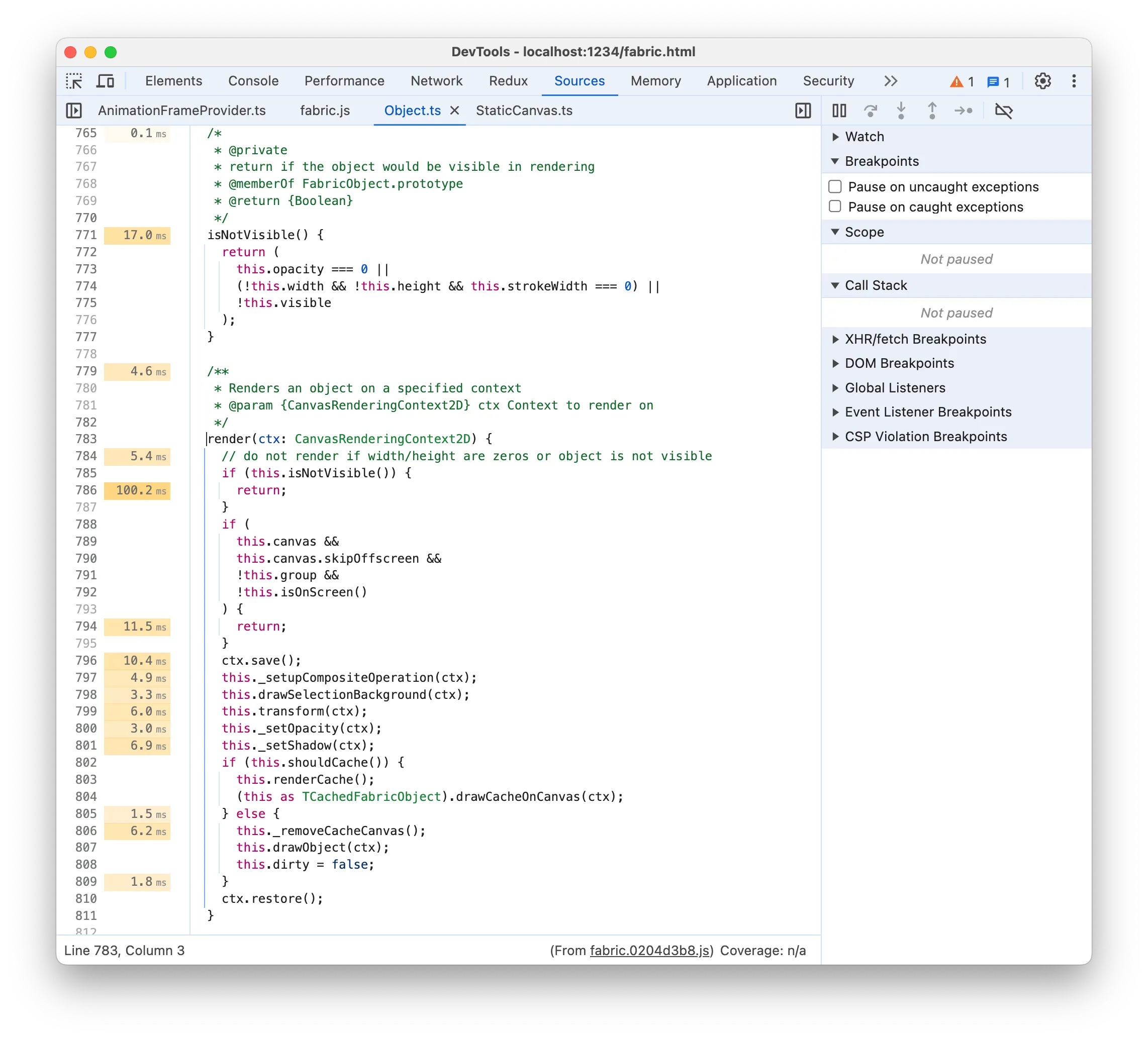
如果您查看左侧的时间标签,您会发现一些非常奇怪的事情,那就是它似乎表明提前返回需要 100ms !我认为 Chrome 中存在一个长期存在的错误,即时间标签的位置不准确。我认为在这种情况下,时间标签大约被一条语句偏移,并且 100 毫秒对应于 if 块,其中 !this.isOnScreen() 检查可能会很昂贵。然而,如果我们回到火焰图,我们通常不会看到任何 isOnScreen 节点作为 render 的子节点,这意味着它实际上并不那么重要。当我们在某个 render 节点下找到它时,它只是一个小节点:
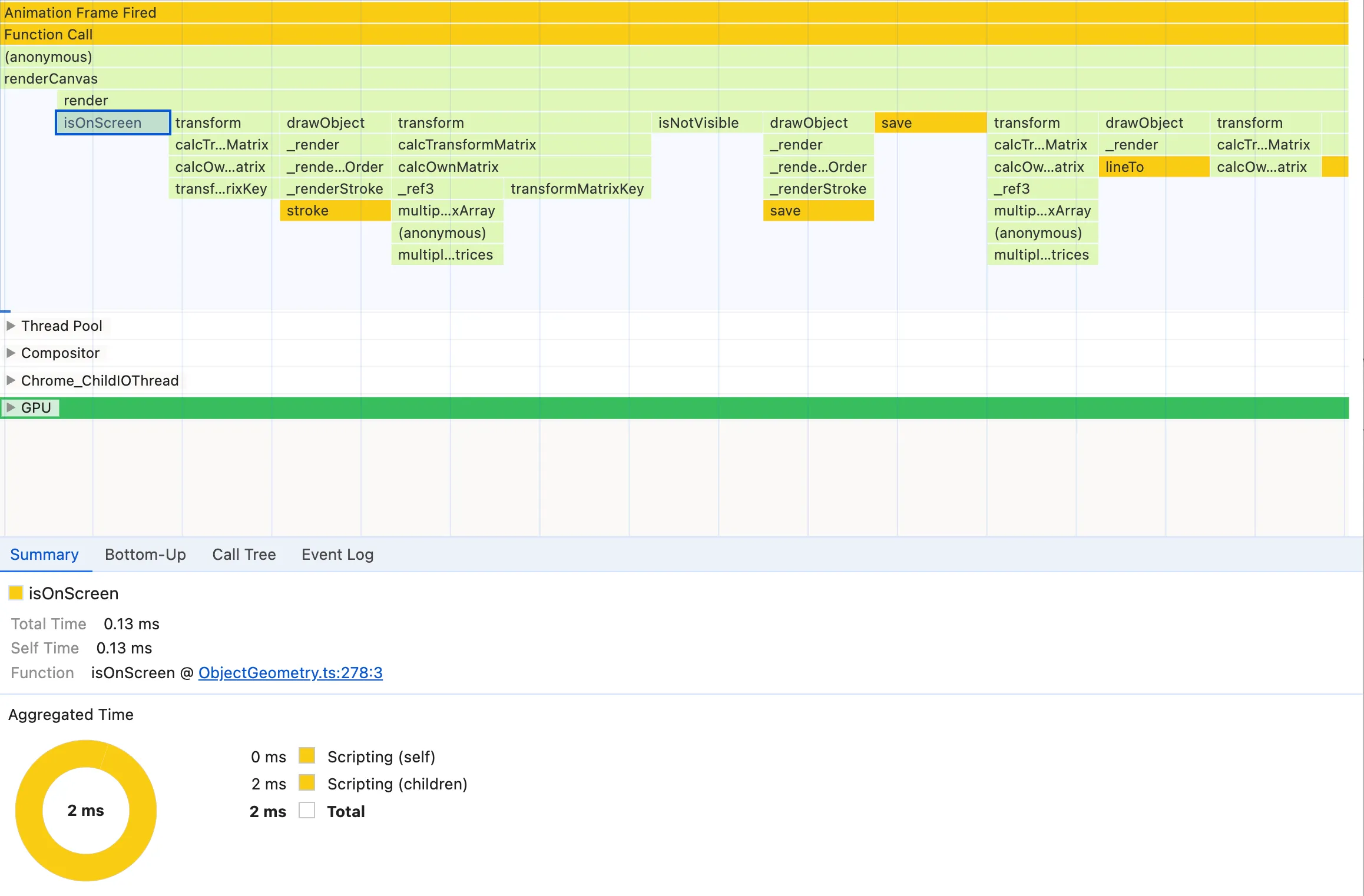
我们可以通过更改 render 方法来排除检查 isOnScreen 来证明它并不那么重要,因为我们所有的对象都在屏幕上并且是动画的。我们再次保存并记录性能:
- 页面 FPS 仪表现在达到 14fps(之前为 12fps)
- 火焰图表中的每个任务现在约为 68 毫秒(之前为 78 毫秒)
这大约是 15% 的改进,这一点也不差,但与人们对Source面板中巨大的时间标签数字的预期相去甚远。这就是为什么我不完全信任Source面板上的时间标签,而掌握阅读火焰图很重要。虽然这是一个很好的改进,我们稍后会应用它,但我们被误导认为 isOnScreen 是罪魁祸首,而我们稍后会发现还有更有效的目标。尤其是对于画布或游戏渲染等复杂代码,将精力集中在改进错误代码上可能会非常耗时。在我们的例子中,我们可以在了解具体情况的情况下删除该检查,但通常您会花费数小时来思考和试验如何提高 isOnScreen 效率。
其余时间标签与火焰图信息一致:有几个函数调用需要一些代码,有些需要更多代码,但它们都没有比其他函数调用更昂贵。
火焰图模式
回到 render 的火焰图,我们在研究火焰图时通常希望寻找这些类型的模式:
- 单个子节点明显大于其他节点,表明例如
render花费了大部分时间执行该功能节点 - 重复频率很高的节点。虽然每个节点不需要太多时间,但如果我们运行效率低下的循环,我们可能会遭受著名的“千次切割死亡”的痛苦
基于这些模式,一些节点引起了我们的注意。
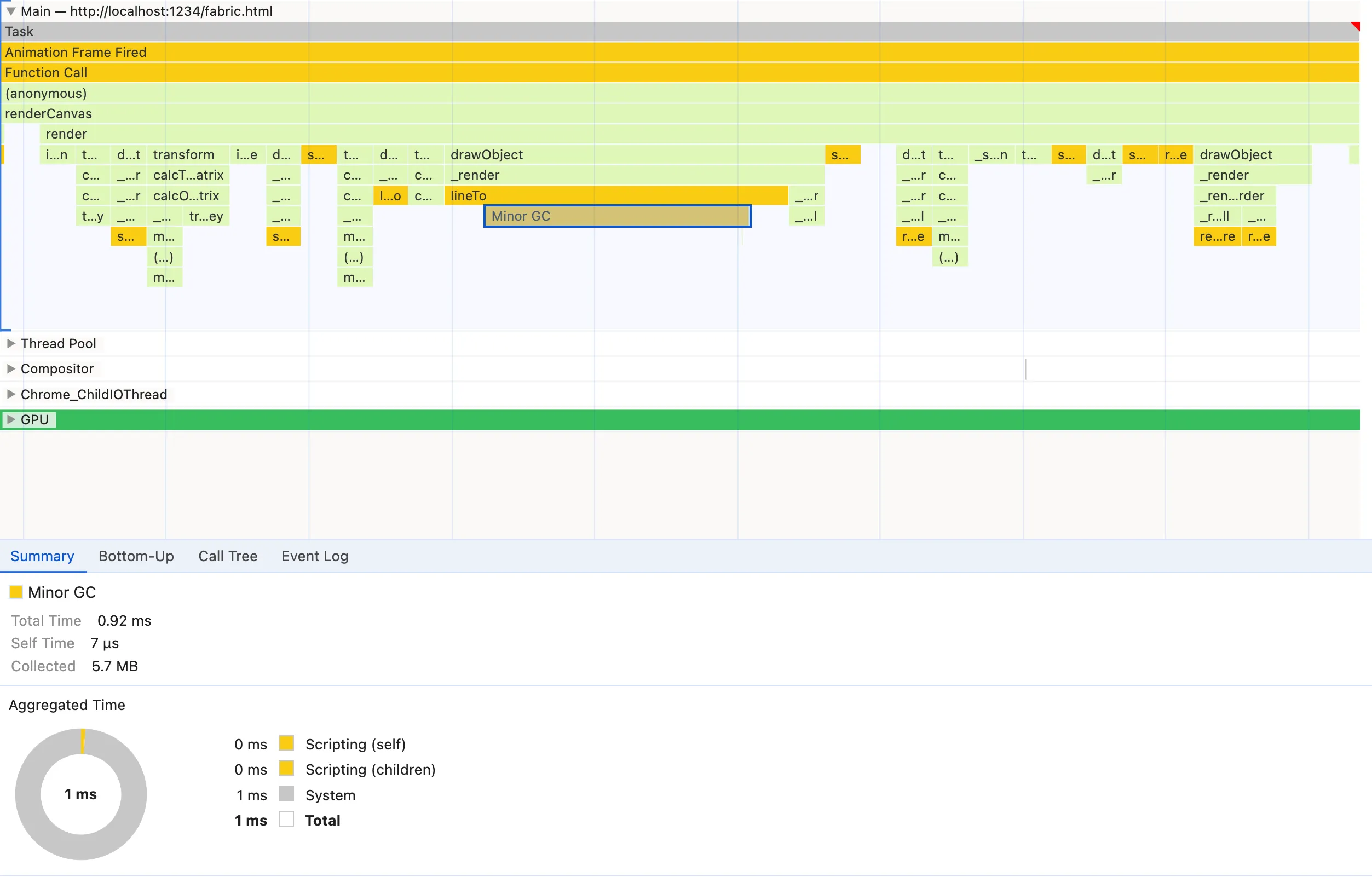
偶尔,但在火焰图表中足够引人注目,会出现 Minor GC(垃圾收集)节点,并且它比其他节点大得多,因此它满足模式1。每个GC 节点都意味着 JavaScript 引擎认为有必要清理内存,并且这是有代价的。GC使得运行时执行时间更难以预测,因为它的调度是不确定的。我们不知道它何时运行以及需要多少时间,从而导致更多的执行时间和不一致的帧速率。
关于火焰图中的
Minor GC节点的一个重要且令人困惑的注释是,它们可能会误导您,让您认为父节点应对糟糕的内存管理负责。
很长一段时间,我也被它欺骗了。在我们的屏幕截图中,我们认为 lineTo 是罪魁祸首,但这怎么可能,因为 lineTo 是原生 CanvasRenderingContext2D 方法!事实上,火焰图会在发生某些事情时向您显示,因此如果GC在 lineTo 执行期间发生,它将显示为其子级。然而,收集的内存是由一个完全不同的函数分配的,如果 CPU 不是那么昂贵的话,它甚至可能不会出现在火焰图中。
不幸的是,检测导致昂贵的不可预测的GC的低效内存分配的根本原因超出了本文的范围。我们将在以后的专门文章中详细讨论内存管理和分析,但幸运的是,稍后将通过解决 CPU 密集型功能来解决该问题。我们代码中的一个函数导致 CPU 执行和内存管理效率低下,因此解决一个问题也可以解决另一个问题。
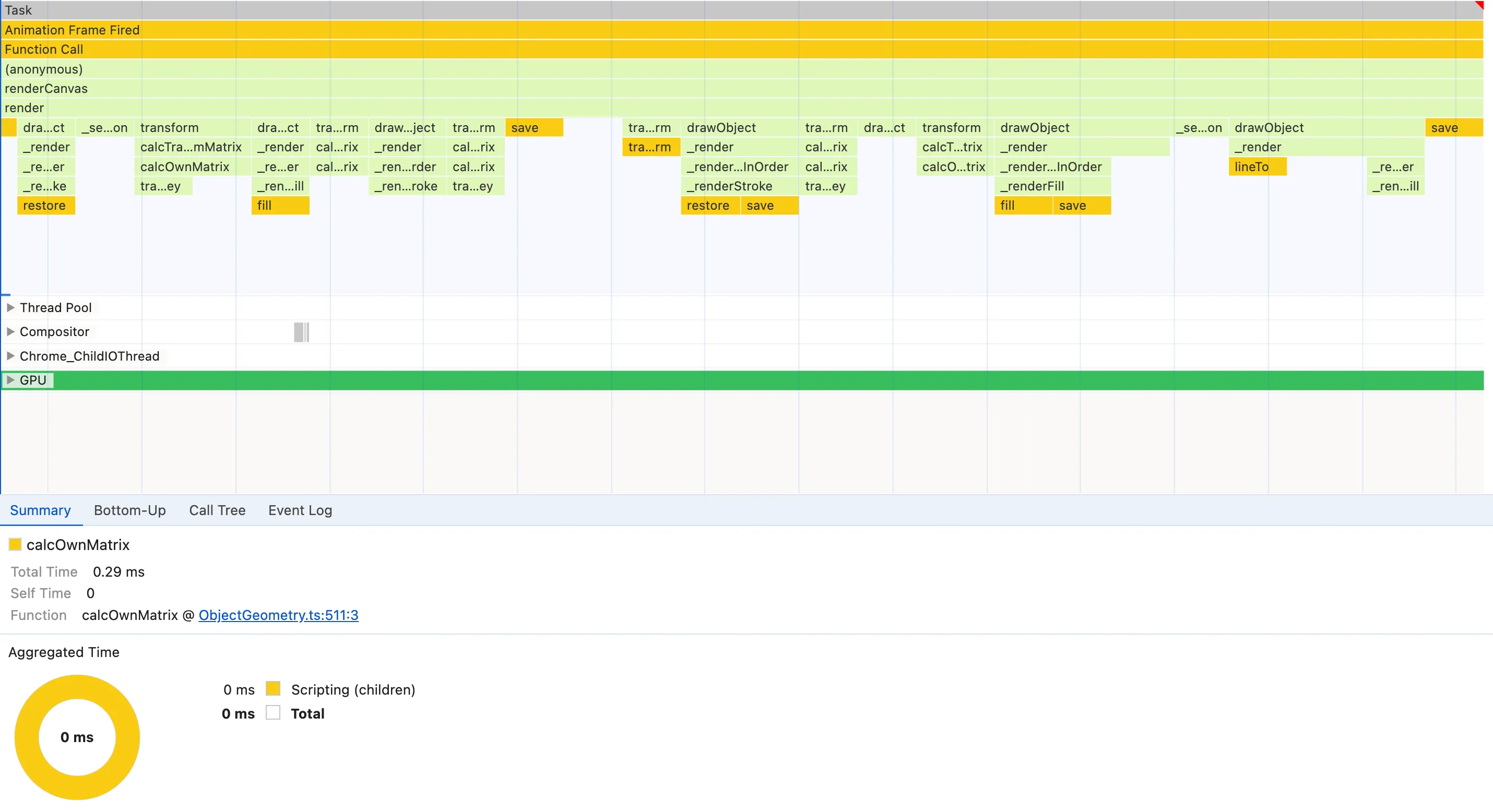
具有 save 、 restore 、 fill 和 lineTo 的节点似乎出现得非常频繁,因此它们满足模式#2。显然,使用它们有一定的成本,而且调用也非常频繁,但很难判断这里是否有任何可能的操作。它们是原生的 CanvasRenderingContext2D ,因此我们无法检查它们以查看实现情况以收集有关我们可以改进的更多信息。那么我们现在继续吧。
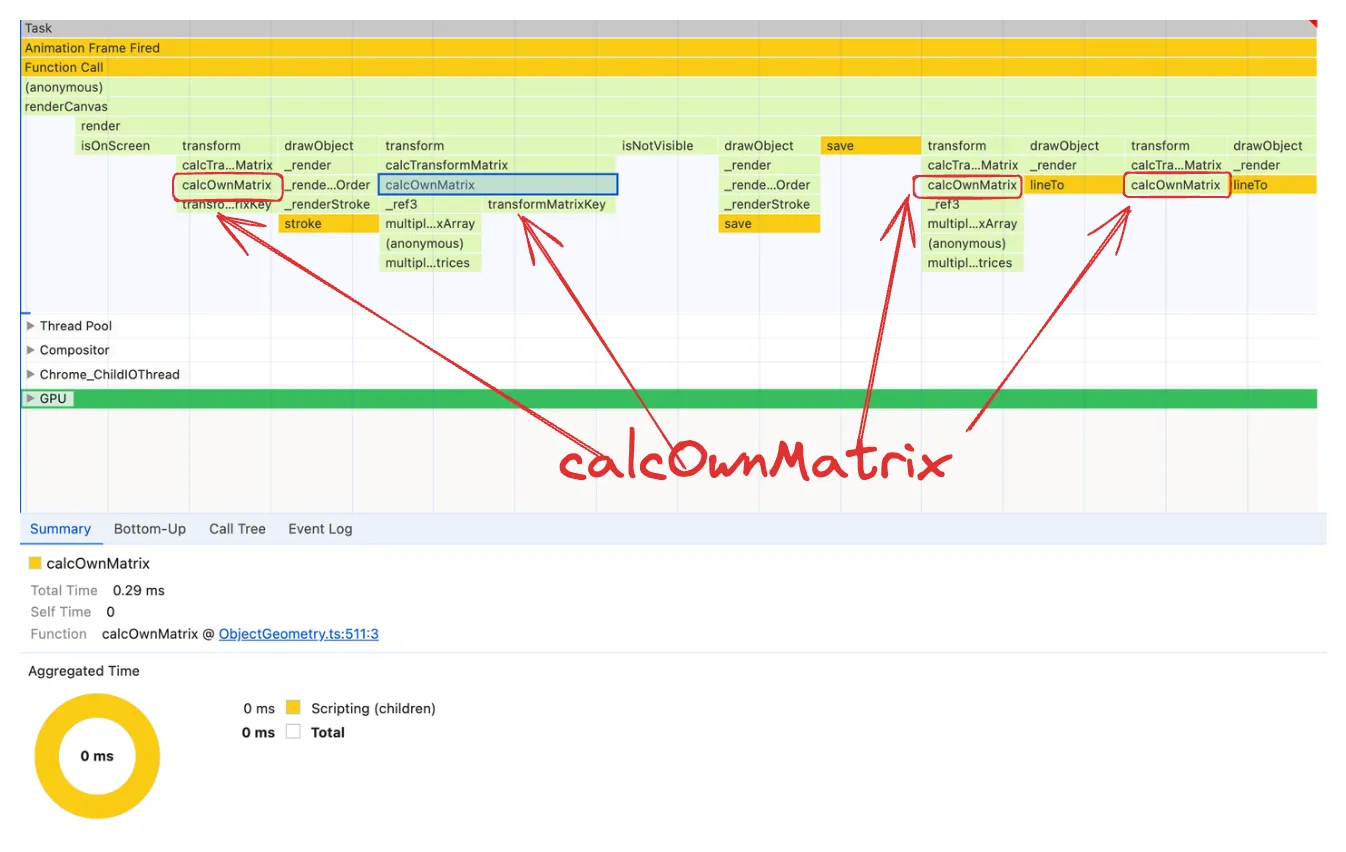
calcOwnMatrix 是火焰图中频繁出现的节点,它也占用了大量的执行时间,因此它满足我们想要寻找的两种火焰图模式。正如我们将看到的,它确实是一个非常好的候选者,但再次很难准确判断它是否有任何问题。另一个疑问是 calcOwnMatrix 或其子节点 transformMatrixKey 和 multiplyTransformMatrices 是否存在问题,因为它们有时会作为子节点出现,且大小与calcOwnMatrix本身相当
因此,火焰图分析为我们提供了一些关于在哪里寻找进一步调查的提示,但如果我们能够获得更多方向,那就太好了。我们想要的是有数字。在进行性能分析时,根据数字做出决策至关重要。自下而上的面板将帮助我们做到这一点。
自下而上(Bottom-Up)分析
自下而上(Bottom-Up)面板包含在选定的时间线范围或选定的火焰图节点内调用的所有函数。然后我们可以按 Self Time(聚合自己的执行时间)或 Total time(聚合自己的执行时间 + 内部调用函数的执行时间)对它们进行排序。 “聚合”是指所选时间线范围或火焰图节点内的总和。该面板之所以被称为Bottom-Up,是因为如果我们展开它,我们可以看到每个函数自下而上的调用堆栈。这对于确定为什么调用昂贵的函数很有用:

然而,为了分析 render 函数的自下而上(Bottom-Up)面板,我们必须做一些有点不直观的事情:选择火焰图中的 renderCanvas 节点。原因是,正如我们所注意到的,火焰图中的 render 函数节点不一致。它们具有不同的宽度/持续时间,根据您选择的特定节点,您将看到自下而上面板中显示不同的功能和执行时间。
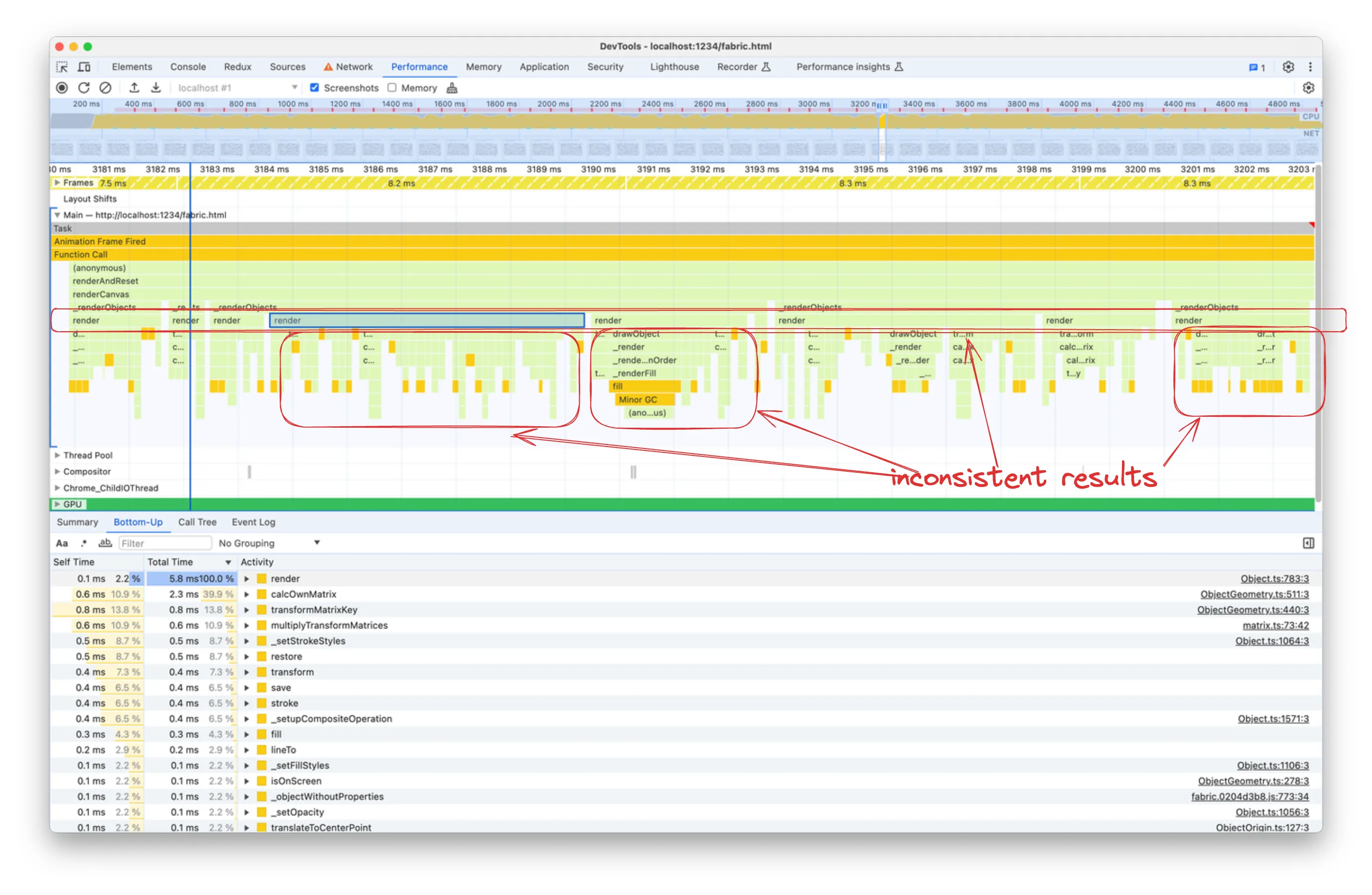
当选择火焰图节点进行分析时,使用更大的聚合时间和更一致的节点会更容易
您会注意到,通过 renderCanvas ,我们拥有更加一致的持续时间和自下而上的列表。
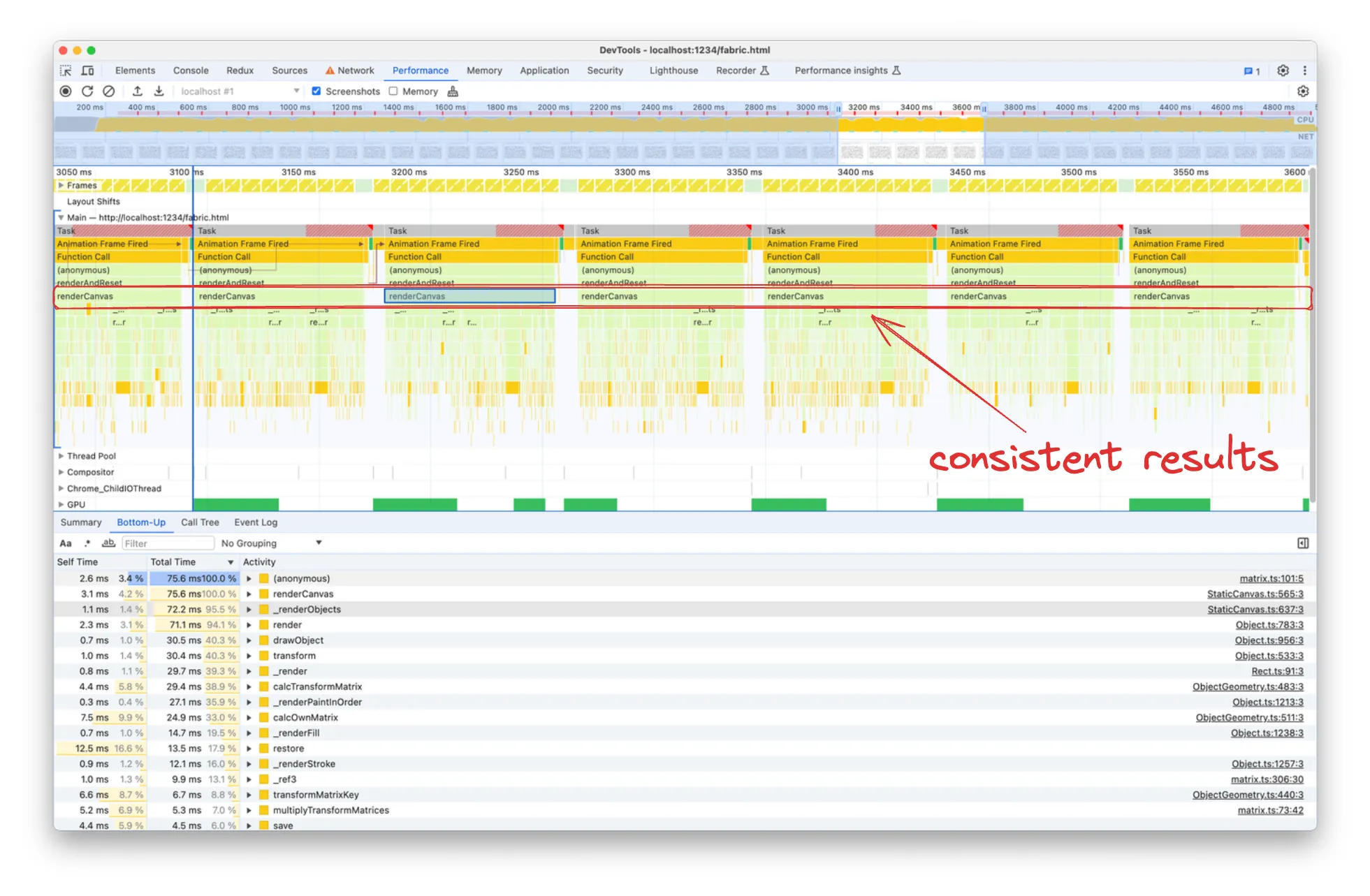
由于 render 是 renderCanvas 火焰图的子图,而前者几乎占用了后者的整个执行时间,因此我们可以预期在两个视图中都会列出相同的昂贵函数。事实上,让我们首先按自时间降序排序,我们会注意到许多顶部结果是 render 调用的函数:
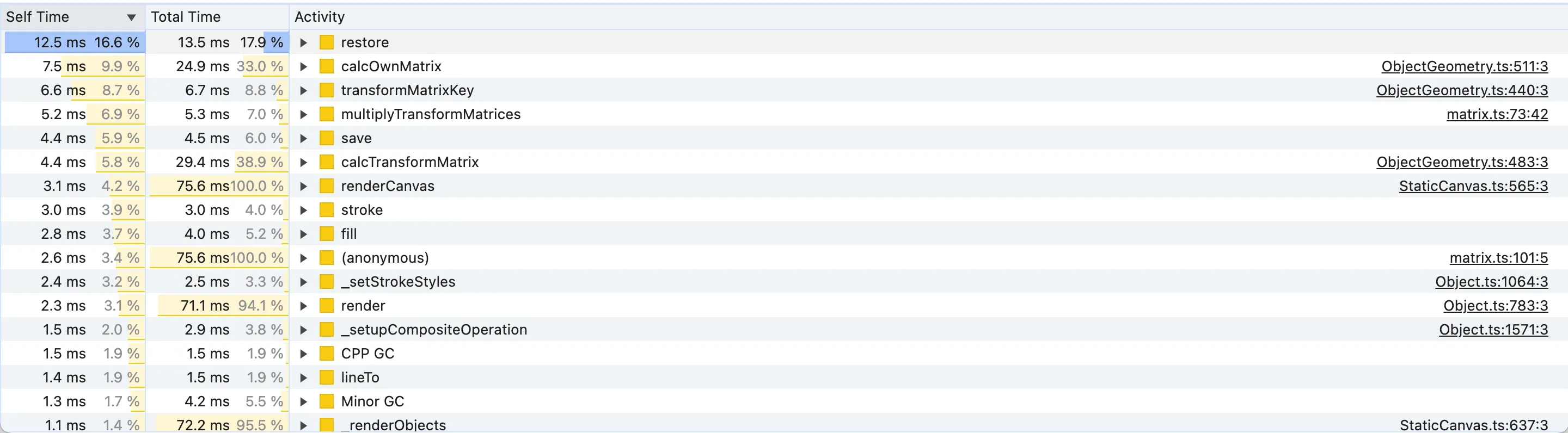
我们有一些潜在的候选者,例如 restore 、 save 、 calcOwnMatrix 、 transformMatrixKey 和 multiplyTransformMatrices 。还值得注意的是,其中三种方法涉及“矩阵”。这是因为画布操作(例如渲染)从根本上需要计算点和对象的几何变换,类似于 translate 、 rotate 或 scale 的 CSS 变换。对于最好奇的你来说,提到的矩阵函数是与标准 JS DOMMatrix 方法等效的fabric.js。如果您想阅读关于为什么 2D 渲染需要矩阵变换的简要说明,您可以阅读游戏开发中的 Dirty Flag 优化模式的“动机”部分。改进矩阵变换计算的众所周知的模式的存在证明了它是昂贵的。因此,如果我们改进矩阵计算,我们也会获得更快的渲染速度。
然而,在开始研究听起来令人恐惧的矩阵变换之前,让我们也按总时间对自下而上列表进行排序:
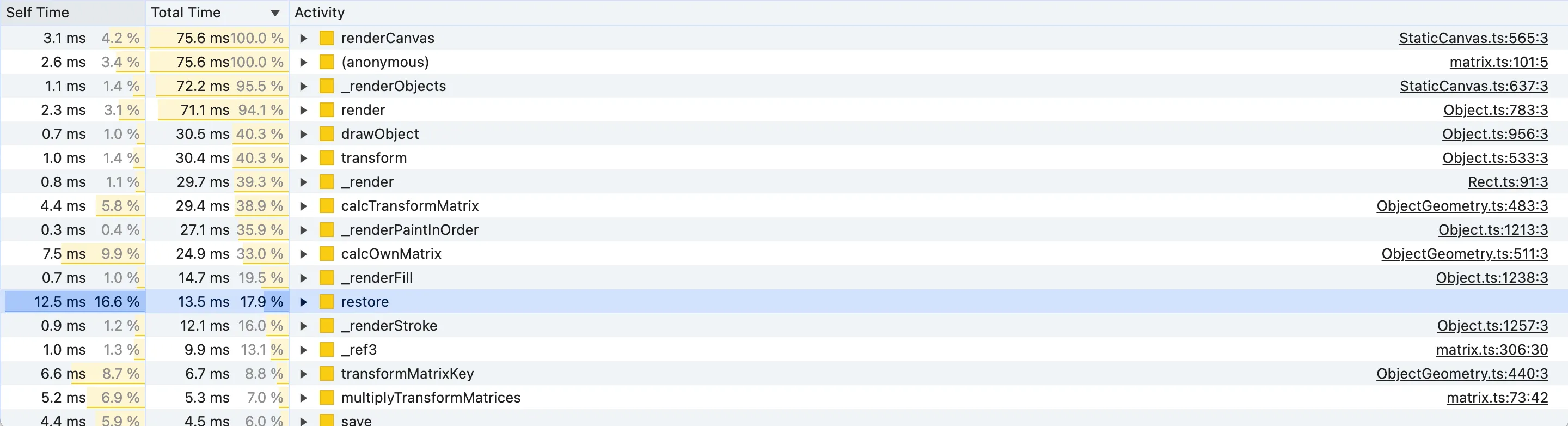
当查看自下而上(Bottom-Up)面板时,我们想要寻找总时间百分比较高的函数,但同时它们不在火焰图中向上。这意味着尽管它们不是高级函数,但它们花费了大量时间,即它们是昂贵的低级函数。
例如, renderCanvas 方法的总时间为 100%,但这很明显,因为它是我们在火焰图中选择的函数! (anonymous) 函数的第二个结果也具有误导性。它具有 100% 的总时间,因为它包含所有匿名函数,包括出于某种原因的 requestAnimationFrame 回调,尽管右侧的源参考可能另有说明。

了解所分析代码的含义对于判断哪些函数尽管处于低级别但具有重要的总时间非常重要。这里有趣的候选者是: transform 、 _render 、 calcOwnMatrix 、 _renderPaintInOrder 、 restore 、 transformMatrixKey 。关于一些功能的一些说明:
drawObject被排除,因为它由render调用,并且仅将对象渲染委托给_render,它也在列表中并且具有类似的总时间,这意味着它实际上是_render运行时的可能原因:
1drawObject(ctx: CanvasRenderingContext2D, forClipping?: boolean) { 2 this._renderBackground(ctx); 3 // ... 4 this._render(ctx); 5}
calcTransformMatrix被类似地排除,因为它调用calcOwnMatrix,它在列表中具有类似的总时间,因此calcTransformMatrix本身没有什么有趣的:
1calcTransformMatrix(skipGroup = false): TMat2D { 2 let matrix = this.calcOwnMatrix(); 3 // ... 4 return matrix; 5}
对 Self Time 和 Total Time 函数的分析似乎都得出结论,我们应该看看与矩阵相关的函数和 save/restore() 。
提高画布渲染性能
现在我们已经有了候选者,让我们尝试深入研究他们。我们将从与矩阵相关的函数开始。我们已经看到 calcOwnMatrix 占用了大量的 Self Time 和 Total Time。
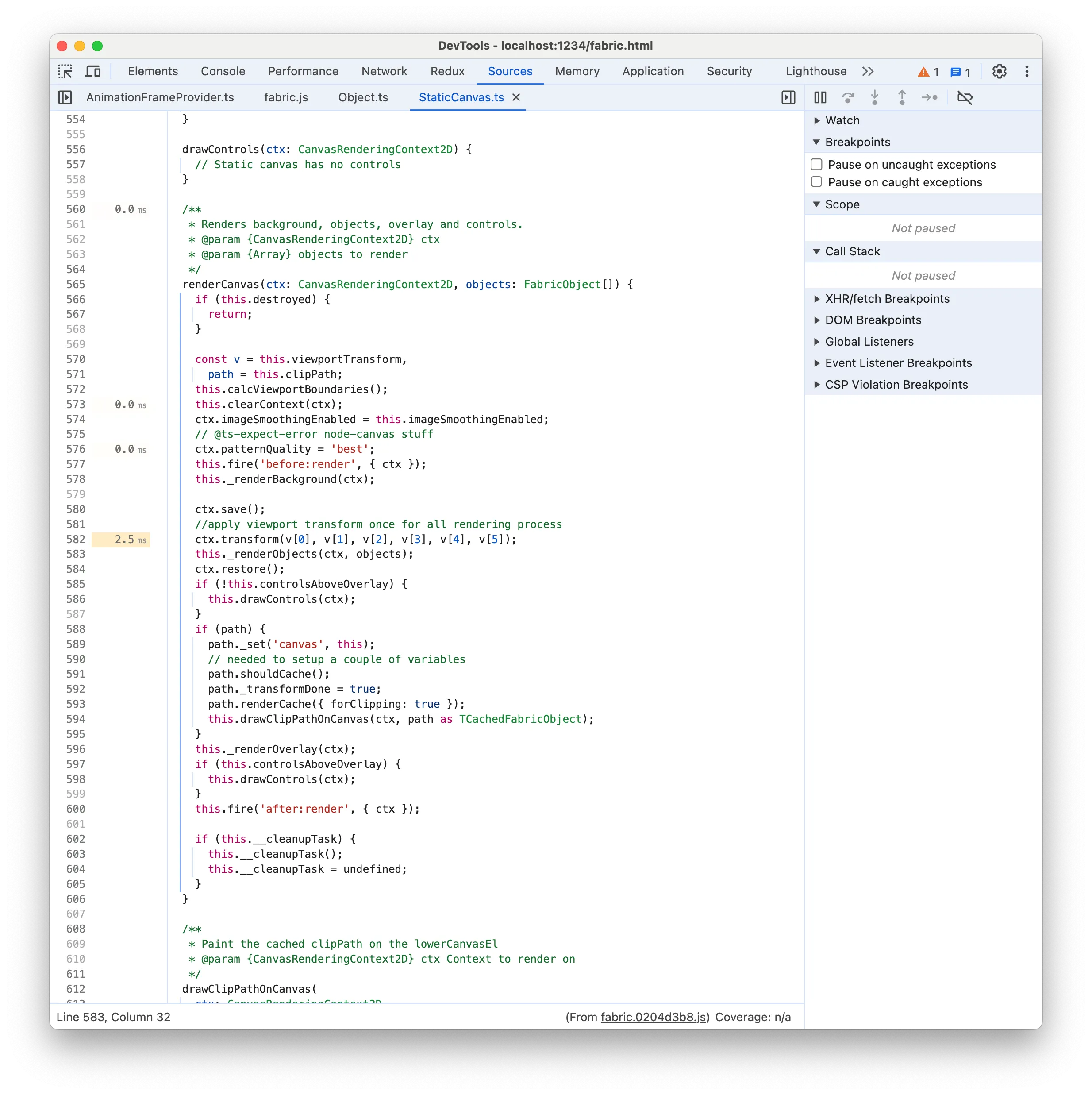
calcOwnMatrix
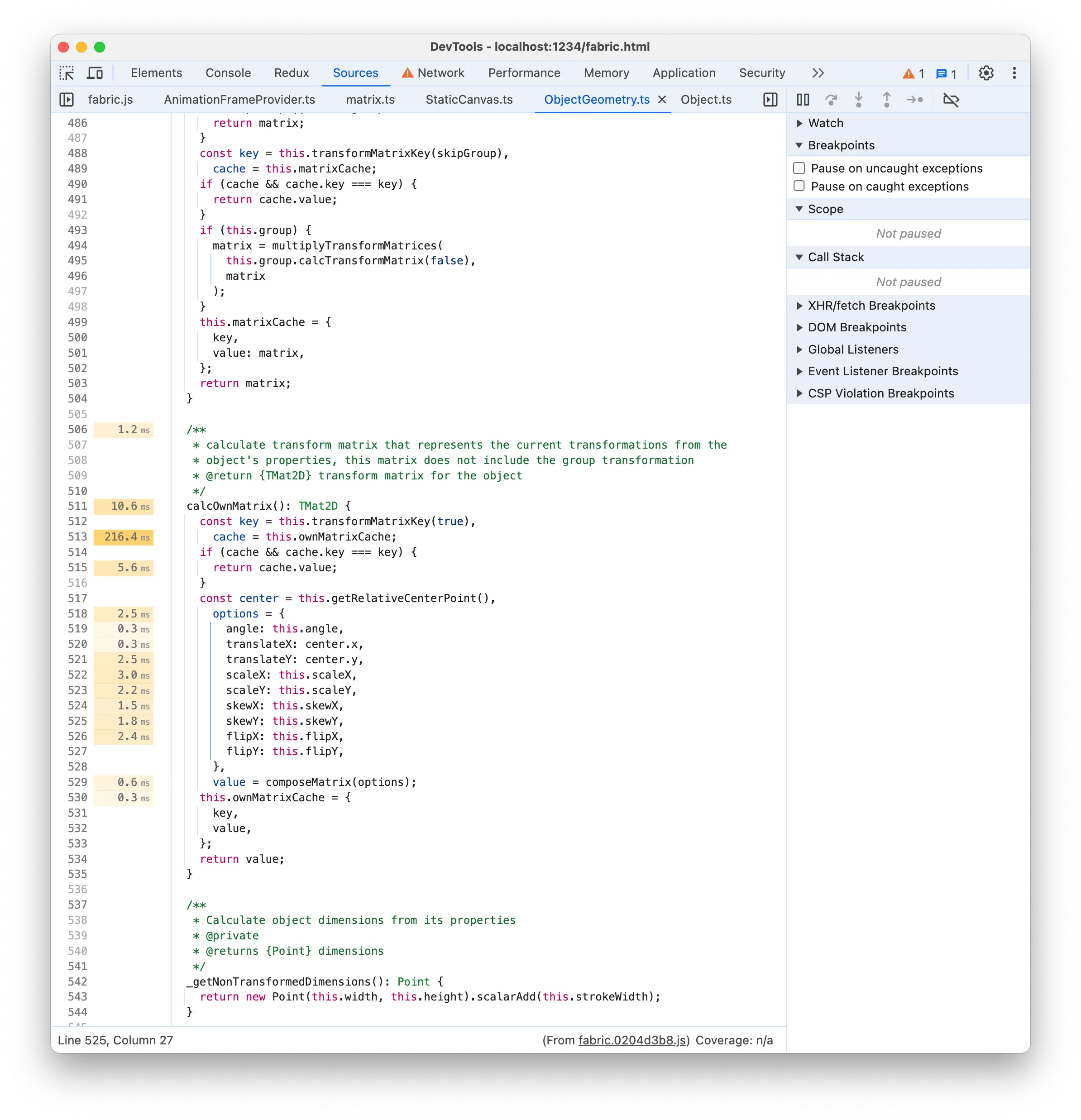 216ms 时间标签似乎表明存在一行昂贵的代码,因为它比其他标签大得多。它指向
216ms 时间标签似乎表明存在一行昂贵的代码,因为它比其他标签大得多。它指向 this.ownMatrixCache 但这没有意义,因为它只是读取一个属性。更合理的是,真正的行是 transformMatrixKey() ,如果你还记得的话,它也被列在昂贵的自下而上函数中!该函数负责获取缓存键以检查变换矩阵是否需要重新计算。查看 transformMatrixKey 源代码实现似乎证实了这一点:
![]()
代码行具有误导性。看代码时,我们可能会认为transformMatrixKey的递归调用很耗费资源,但在我们的基准测试矩形中并没有this.group属性,因为没有分组。问题的代码行是返回指令,它创建了一个长字符串作为缓存。使用像JavaScript这样高级的语言,不必处理服务器上的10万个网络请求,通常意味着我们不需要担心低级问题,如字符串性能。但如果不小心,我们仍然需要为昂贵的操作付出代价。创建和比较大字符串可能会很快变得昂贵,如这个大字符串比较基准所示。
考虑到我们正在制作动画,因此矩形不断改变位置,使用缓存只是不必要的开销,因此我们可以尝试完全删除矩阵缓存。在大多数情况下,您可能会尝试考虑更有效的缓存键,但这超出了本文的范围。
因此,让我们创建自己的 OptimisedRect 并覆盖 calcOwnMatrix 以避免使用缓存。如果我们重新加载页面并再次记录性能,我们会注意到显着的改进。在我的 M2 Pro 上:
- 页面 FPS 仪表现在达到 16fps(之前为 13fps)
- 火焰图表中的每个任务现在约为 65 毫秒(之前为 77 毫秒)
calcOwnMatrix源不再显示 216ms 的时间标签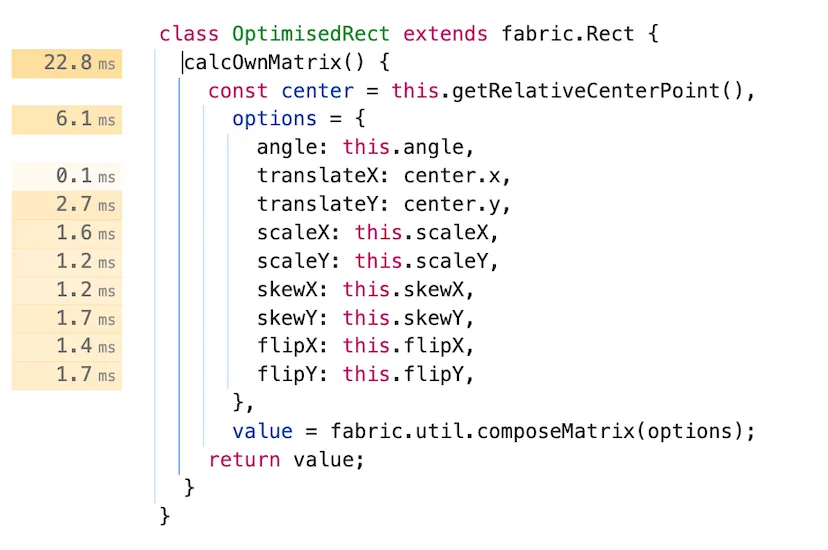
总体而言,提高了 20%。
CanvasRenderingContext2D save/restore
基于自下而上分析的下一个候选是 ctx.save/restore() 。这是一个高度针对画布的优化,但似乎使用保存和恢复画布绘制状态具有不可忽略的成本。成本似乎取决于 GPU 和 2D 上下文状态。使用自下而上面板,我们可以看到谁调用了 save/restore :
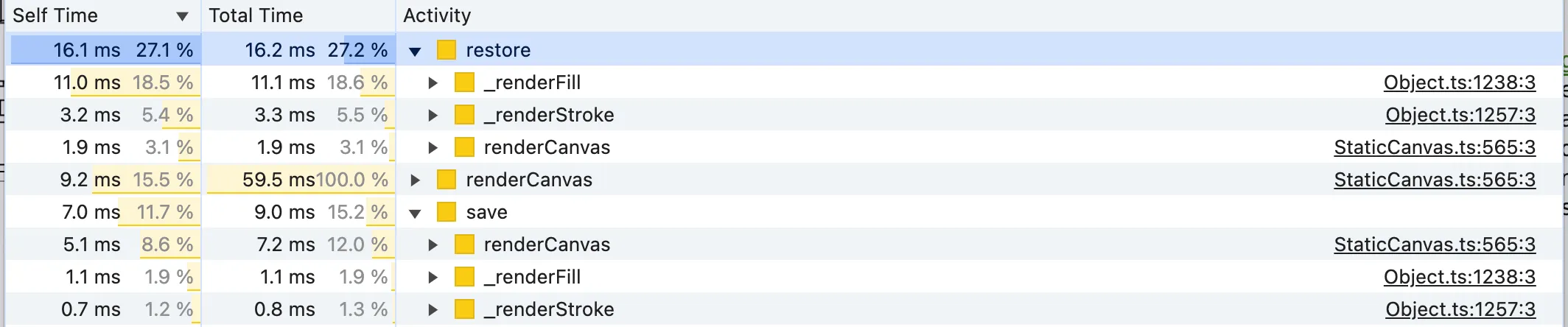
让我们检查一下 _renderFill 和 _renderStroke 的来源:
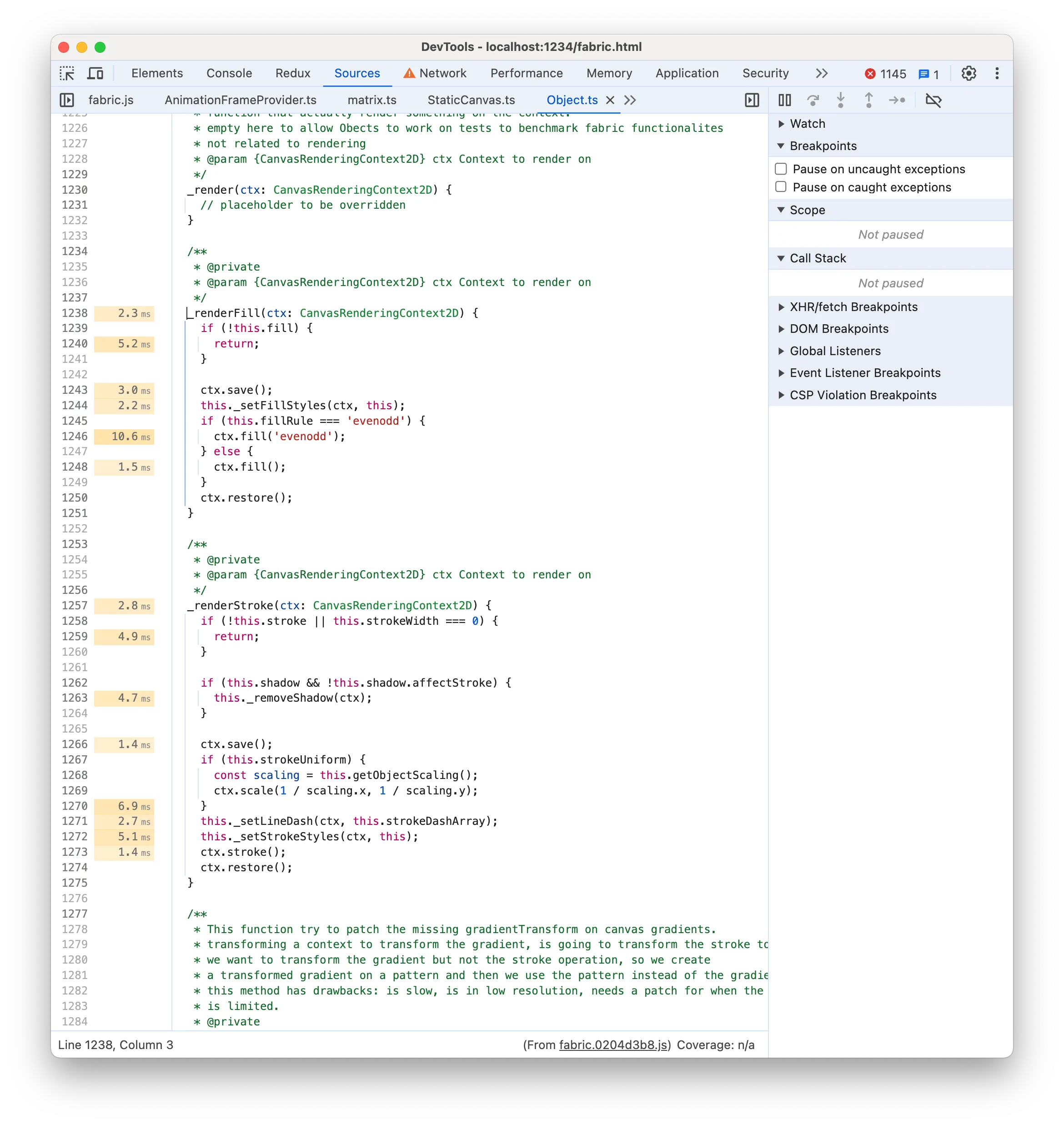
没有什么特别值得注意的,但确实 ctx.save/restore 对于填充和描边矩形来说是不必要的。我们没有使用任何像 strokeUniform 这样的功能(无论父组比例如何,都渲染统一的矩形边框),并且 Fabric.js 已经为每个调用 ctx.save/restore() (即推送新的绘图状态)正确的 render 调用。因此,在渲染描边或填充之前执行此操作是浪费的。
我们再次保存并记录性能:
- 页面 FPS 仪表现在达到 20fps(之前为 16fps)
- 火焰图表中的每个任务现在约为 50 毫秒(之前为 65 毫秒)
这额外提升了约 25%,我们至少接近 24fps!
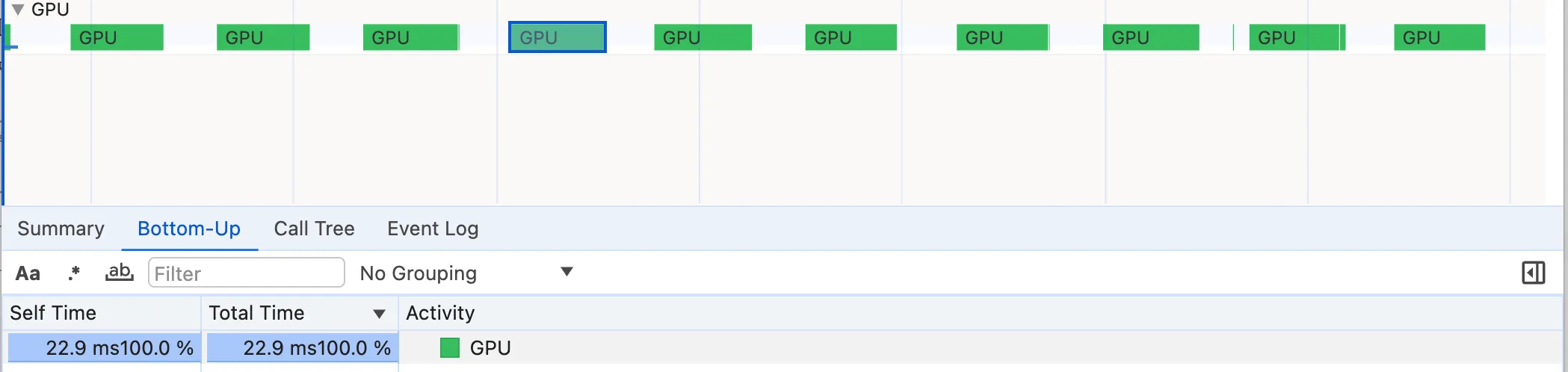
beginPath 与 fillRect GPU 时间
根据自下而上列表,我们的下一个目标是 _render ,它使用画布 2D 操作渲染矩形:
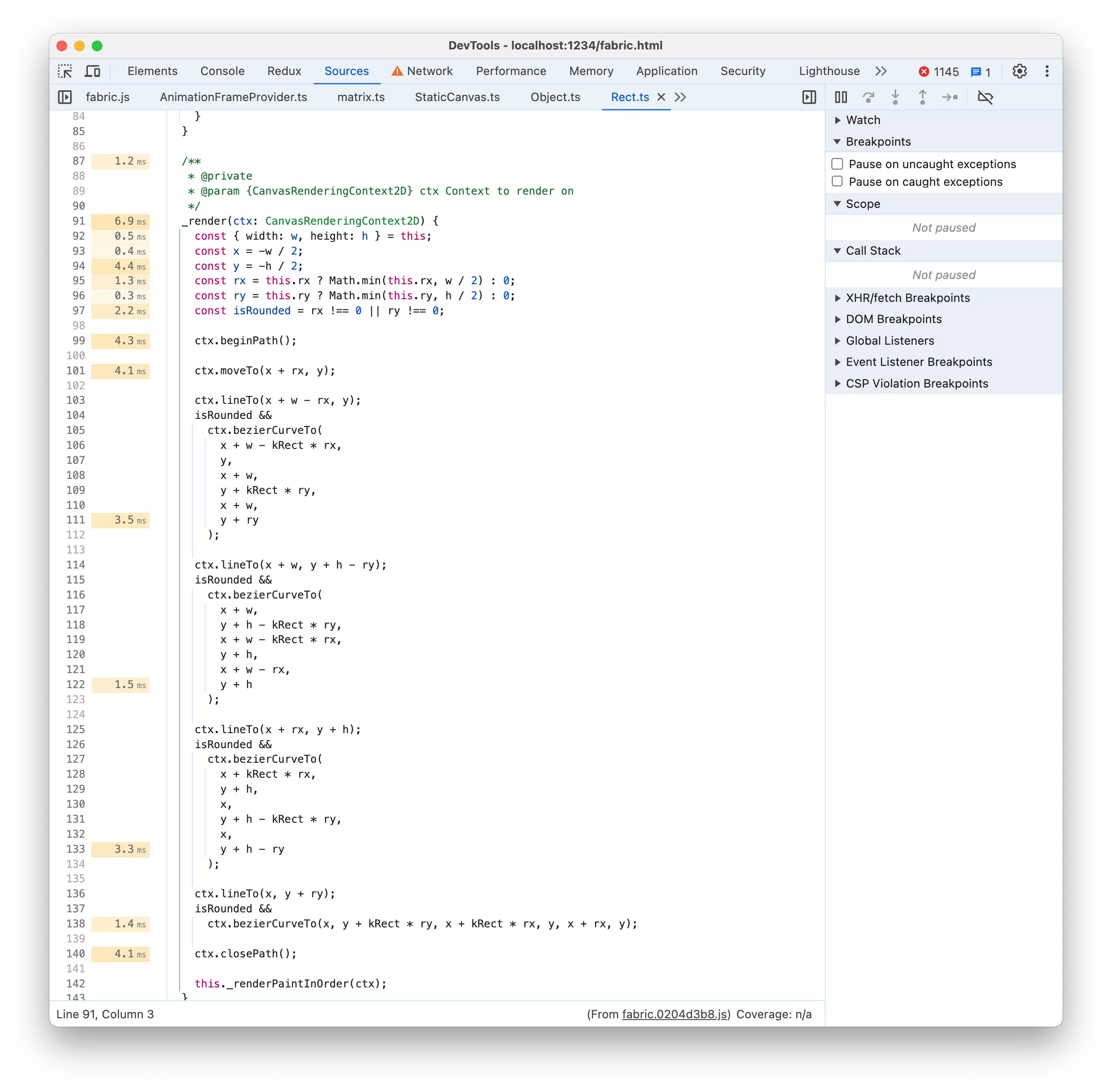
当您只需执行 strokeRect 和 fillRect 并获得相同的结果时,使用 2D Path 命令的组合渲染简单的矩形似乎没有必要。让我们尝试一下:
1_render(ctx) { 2 ctx.strokeRect(-this.width / 2, -this.height / 2, this.width, this.height); 3 ctx.fillStyle = 'white'; 4 ctx.fillRect(-this.width / 2, -this.height / 2, this.width, this.height); 5}
请注意,我们通过直接调用 strokeRect 和 fillRect 替换了 2D Path 命令以及 _renderFill 和 _renderStroke 函数。
我们再次保存并记录性能:
- 页面 FPS 仪表现在达到 28fps(之前为 20fps)
- 火焰图表中的每个任务现在约为 32 毫秒(之前为 50 毫秒)
这又增加了约 40%,我们已经达到了 24fps 的目标!
这可能会让人感到惊讶,因为源时间(Source Time)标签没有显示显着的数字。然而,如果我们比较 GPU 时间,我们会发现从 39 毫秒大幅减少到 23 毫秒。很难确切说明为什么 GPU 执行 fillRect 指令比 beginPath 指令快。我大胆猜测,这是因为一系列直接 fillRect 和 strokeRect 指令更容易由 GPU 并行化和执行。如果您知道更好,请发表评论。
我们更新后的按总时间排序的自下而上列表现在主要包含矩阵函数,特别是 transform 、 calcOwnMatrix 、 multiplyTransformMatrixArray 和 multiplyTransformMatrices 。到目前为止,我们已经避免深入研究这些可怕的数学函数,但似乎是时候解决它们了!
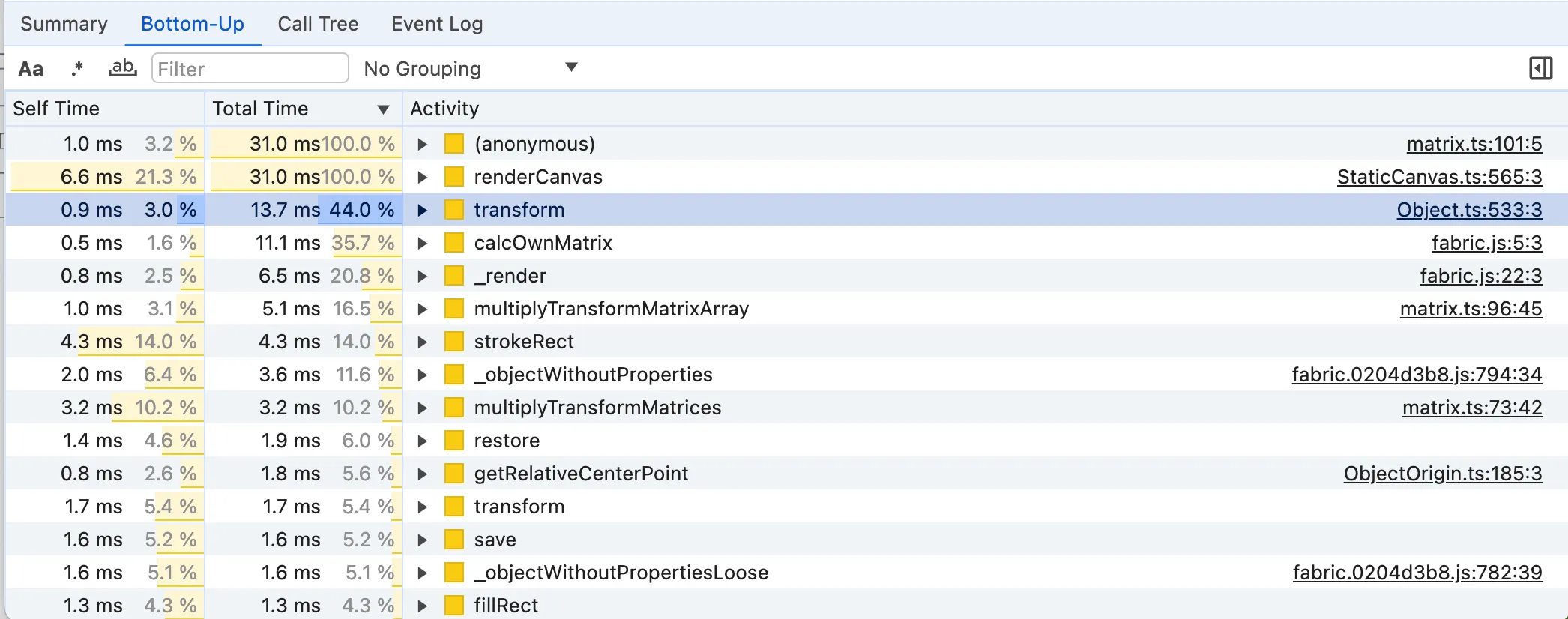
multiplyTransformMatrixArray 和 multiplyTransformMatrices 是原始矩阵计算函数。
1const multiplyTransformMatrixArray = ( 2 matrices: (TMat2D | undefined | null | false)[], 3 is2x2?: boolean 4) => 5 matrices.reduceRight( 6 (product: TMat2D, curr) => 7 curr ? multiplyTransformMatrices(curr, product, is2x2) : product, 8 iMatrix 9 ); 10 11const multiplyTransformMatrices = ( 12 a: TMat2D, 13 b: TMat2D, 14 is2x2?: boolean 15): TMat2D => 16 [ 17 a[0] * b[0] + a[2] * b[1], 18 a[1] * b[0] + a[3] * b[1], 19 a[0] * b[2] + a[2] * b[3], 20 a[1] * b[2] + a[3] * b[3], 21 is2x2 ? 0 : a[0] * b[4] + a[2] * b[5] + a[4], 22 is2x2 ? 0 : a[1] * b[4] + a[3] * b[5] + a[5], 23 ] as TMat2D;
除非有人知道如何释放恶魔般的按位运算,否则很难进一步改进它们。即便如此,我仍然怀疑是否有可能发生重大改变。
如果我们查看 transform ,我们会注意到它在内部调用 calcOwnMatrix :
1transform(ctx: CanvasRenderingContext2D) { 2 // ... 3 const m = this.calcTransformMatrix(true); 4 ctx.transform(m[0], m[1], m[2], m[3], m[4], m[5]); 5}
尽管我们已经优化了 calcOwnMatrix 以避免使用缓存键,但它仍然占总时间的很大一部分。然而,我们意识到我们的矩形始终只是在动画中平移,因此不需要计算 calcOwnMatrix 中的完整通用矩阵,考虑到缩放、旋转等。
1calcOwnMatrix() { 2 const center = this.getRelativeCenterPoint(); 3 const matrix = fabric.util.createTranslateMatrix(center.x, center.y) 4 return matrix; 5}
我们再次保存并记录性能:
- 页面 FPS 仪表现在达到 36fps(之前为 28fps)
- 火焰图表中的每个任务现在约为 22 毫秒(之前为 32 毫秒)
这又是约 30% 的改进,现在基准测试运行顺利!您的计算机可能也不会转动风扇。我们成功了!
最后看一下性能记录
这是我们旅程开始时的性能记录:
这是我们在分析指导下进行优化后的性能记录:
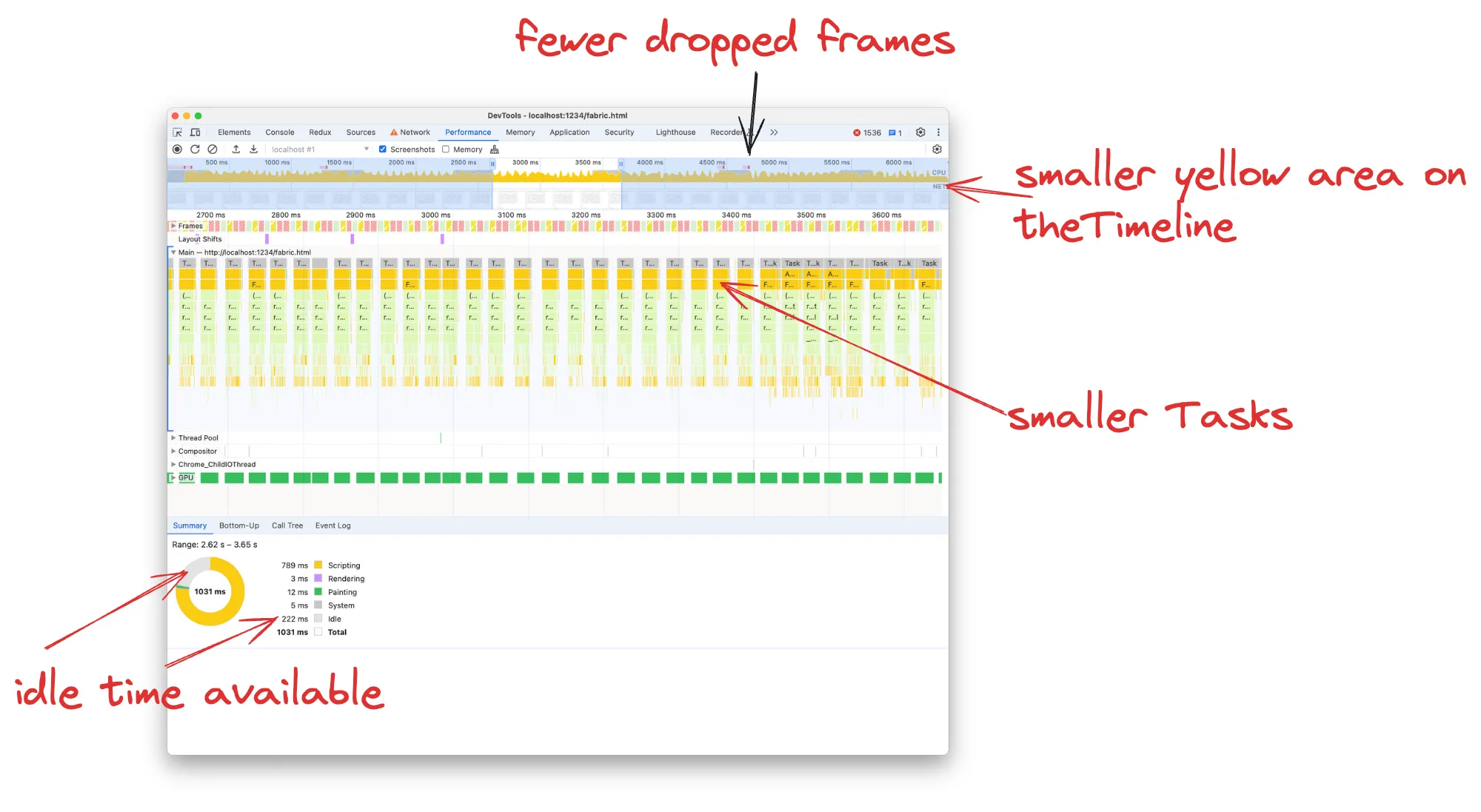
在时间轴上,我们现在可以看到整体黄色区域减少,这意味着我们执行的 JavaScript 减少了。在时间轴的顶部,我们曾经有一条全角红线表示连续丢帧,而现在只是偶尔丢帧。
火焰图中的每个任务现在需要约 20 毫秒,而不是 77 毫秒,因此我们也没有关于“长任务”的红色警告。最终的基准 FPS 仪表显示 36 fps,而 Chrome Devtools FPS 仪表甚至显示 54 fps

感谢您到目前为止的阅读,如果您认为本文有用,请发表评论。下一篇文章将介绍内存分析。
公众号关注一波~

网站源码:linxiaowu66 · 豆米的博客
Follow:linxiaowu66 · Github
关于评论和留言
如果对本文 Chrome DevTools的性能分析的综合指南(翻译) 的内容有疑问,请在下面的评论系统中留言,谢谢。